摘要
手动搭建AI工作流耗时费力?DeepWiki自动生成n8n工作流,解决代码理解难、文档缺失痛点,10分钟完成从逻辑梳理到落地,效率提升90%。

现在是 AI 编程时代,什么都可以用 AI 来开发了,但一个正儿八经的项目还是需要很多考量的。
所以开发的第一禁忌是从 0 开始造轮子,正确的打开方式是直接拿别人跑通的项目来改。
话虽这么说,对小白来说这也很难,1 是要重新理解别人项目的逻辑,2 是改功能很容易改出 bug
怎么办?难道要让小白从头学代码了吗?
DeepWiki 就是为了解决这个问题而生。
DeepWiki 是什么?
Devin 知道吗?这是一款跟 Cursor 一样的头部 AI 编程工具。而 DeepWiki 就是它的母公司开发的,**定位是 Github 开源项目的百科全书,**说白了就是为了帮我们小白进一步降低 AI 编程门槛。
划重点:
-
免费使用。
-
目前已索引了超过 3 万个热门 GitHub 仓库。
我们可以通过访问 https://deepwiki.com,或者将 GitHub 仓库链接中的 github 替换为 deepwiki 来使用。
DeepWiki 解决了什么问题?
DeepWiki 主要解决了开发者在阅读和理解 GitHub 开源项目源代码时遇到的诸多痛点,包括:
-
语言障碍: 现在 GitHub 很多项目都是纯英文的,专业术语翻译过来有时比较别扭,用 DW 就没这个问题了。
-
文档缺失或不完善: 许多仓库缺乏完善的 README 甚至没有文档,DeepWiki 能够基于源码和其他信息自动生成文档,避免开发者需要直接啃代码或在 Issues 中搜索信息。
-
代码量庞大难以理解: 当项目文件数量巨大、代码行数极多时,DeepWiki 可以帮助开发者快速建立项目的宏观认知,例如通过生成系统架构图,理清项目整体脉络。
-
人工阅读效率低下: 面对海量的开源项目和代码更新,纯粹依靠人力阅读和总结是不现实的,DeepWiki 提供了自动化的解决方案。
-
功能与源码难以对应: 传统的项目文档往往缺乏功能与具体代码实现之间的映射关系,DeepWiki 能够通过源码分析,在对话中提供功能讲解甚至代码级别的实现细节。
-
缺乏项目全局视角: GitHub 本身提供的代码浏览功能和 GitHub Copilot 等工具侧重于局部代码理解,DeepWiki 则通过分层分析和构建文件关联图等方式,帮助用户从整体上把握项目架构和内部逻辑关系。
在提问的时候,它会深度查询项目的各个部分,如下图是我后面会讲到的实践中的一环,右边已经在拼命阅读源码,这不比我们自己去看要有效率的多吗?
实践
之前我们介绍过 n8n,是最灵活的自动化工具(见 gzh:饼干哥哥 AGI ),可以轻松完成一个 AI 工作流的搭建。
下面是我应用在我教育业务里的小红书全自动生产 n8n 工作流。
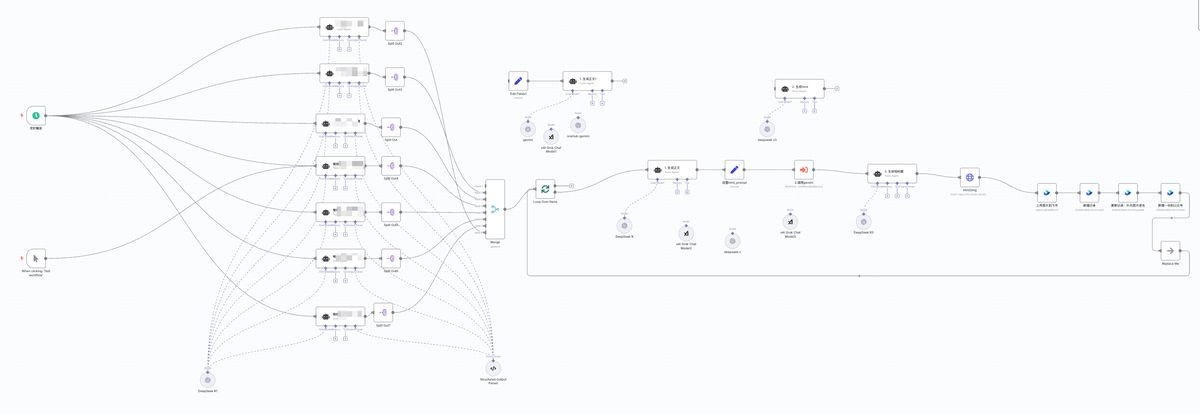
但对小白来说还是会经常踩坑,搭流程来还是很费时间的,有没有可能让 AI 自动搭流程呢?
n8n 的节点是通过 json 形式来呈现的,如果我们可以用 deepwiki 的功能来问 n8n 项目,那我们只需要把功能需求沟通清楚,理论上工作流就能直接产出并贴到 n8n 上。
正好我准备把我原先在本地跑的 python 工作流(全自动 AI 小红书封面内容生成)改到 n8n 上,就拿这个来做实操。
在开始之前,我们先用常规的大模型来试一下,直接跑的话效果是什么样的?
这里我用 Grok(试了其他的例如 Gemini,生成的 json 文件会被截断,最终还是 Grok 靠谱一些)
操作很简单,就直接在对话框里把我原先的 py 文件扔进去,让它生成 n8n 工作流的 json

然后把生成好的 Json 上传到 n8n,发现并不是完整的工作流,而且还选错了节点:大模型应该导入的是「AI Agent」再加 chat model。当然,对于刚接触的同学来说也不知道,所以这个流程根本无法用。
接下来,我们来看下 DeepWiki 的效果。
我试过直接把我的 python 文件扔给 Deepwiki 去生成 n8n 工作流 Json,出来的代码会被截断,可能是上下文太短了,又或者是哪里出问题。
后来我改成,用 grok 或 gemini 去理解我的 python 文件,生成能让 deepwiki 理解的工作流逻辑描述,然后再把后者扔给 Deepwiki 生成工作流。这也是用 DeepWiki 自动生成 AI 工作流的核心逻辑。
生成工作流逻辑描述
提示词:
我在开发n8n工作流,并计划用deepwiki帮我生成n8n的工作流json文件,现在需要你帮我根据以下python文件,生成好工作流的描述和逻辑,讲清楚1、2、3的流程是什么样的,需要什么节点,用中文回复:
我的 python 文件
这里也可以改成讲你的想法是什么样的,然后让 AI 帮你完善。
得到的描述,逻辑非常清晰了:
Gemini:
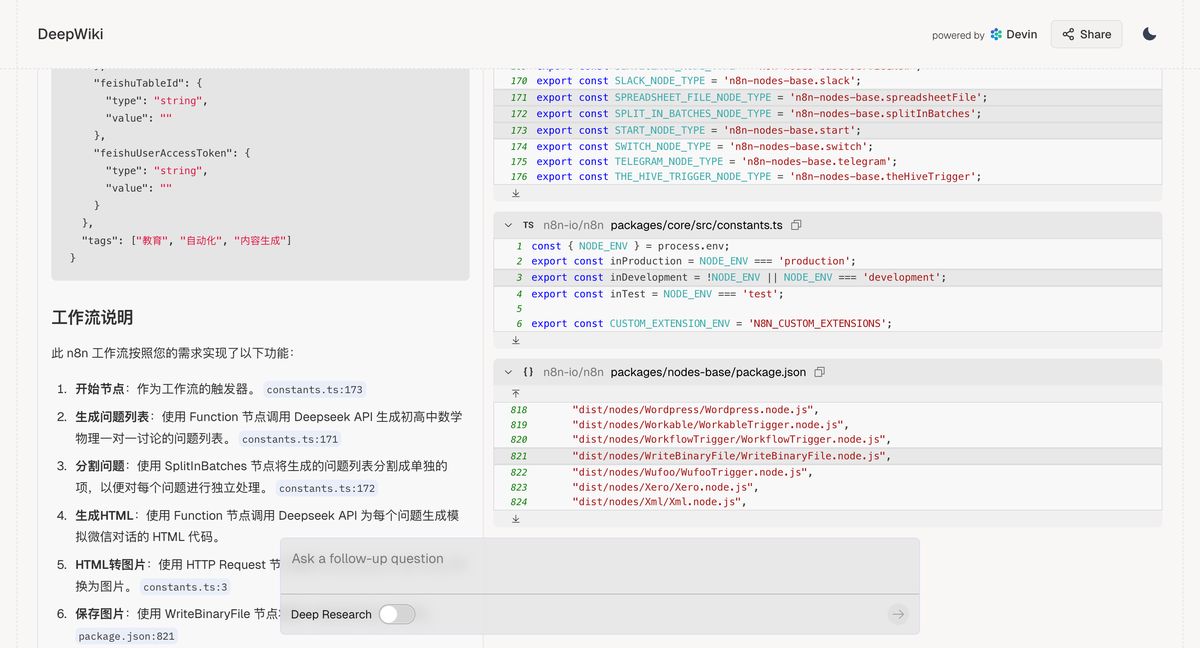
好的,我已经仔细阅读了你的 Python 文件。这个脚本的主要目的是根据一系列问题,生成用于小红书封面的 HTML 图片,并附带一段针对该问题的教育短文,最后将问题、生成的 HTML、图片路径、短标题和正文内容保存到 CSV 文件,并且同步到飞书的数据表中。
下面我将详细解释脚本的流程和所需的 n8n 节点:
整体流程可以分为以下几个步骤:
-
生成问题列表: 脚本首先通过调用 AI 模型(
deepseek-v3-250324)生成一个包含多个关于 xxx 的选题列表。 -
处理每个问题: 脚本会遍历生成的问题列表,对每个问题执行以下操作:
- 生成 HTML: 调用 AI 模型(
deepseek-v3-250324)根据当前问题,生成一段模仿微信对话形式的 HTML 代码,这段 HTML 旨在作为小红书的封面图片。 - 生成图片: 使用
html2img库将上一步生成的 HTML 内容转换为图片,并保存到本地指定的图片目录下。 - 上传图片到七牛云: 将生成的本地图片上传到七牛云存储,并获取图片的 URL 地址。
- 生成正文: 调用 AI 模型(
ep-20250214150946-wf8m6)根据当前问题,生成一篇关于一对一严肃教育的短文,字数在 500 字左右,纯文本格式。 - 保存到飞书: 将问题、上传到七牛云的图片 URL、问题本身作为短标题以及生成的正文内容同步到飞书的指定数据表中,并将本地图片作为附件上传到飞书记录中。
- 生成 HTML: 调用 AI 模型(
-
初始化和配置: 脚本在运行前会确保输出目录存在,初始化 CSV 文件,并尝试初始化飞书的数据表结构。它还会生成一个包含当前批次信息的文本文件。
对应到 n8n 工作流,你需要以下节点:
-
Start 节点: 作为工作流的触发器。你可以根据需要选择合适的触发方式,例如定时触发或者手动触发。
-
Function 节点 (生成问题列表):
- 功能: 调用 AI 模型生成问题列表。
- 代码: 你需要将 Python 代码中生成问题列表的部分(
system_role和调用send_to_ai函数)移植到这个 Function 节点中。你需要配置 OpenAI API 的密钥和基础 URL。 - 输出: 这个节点应该输出一个包含问题列表的 JSON 数组。每个数组元素是一个包含单个问题的字符串。
-
Split Out 节点:
- 功能: 将上一步生成的问题列表分割成单独的 item,以便后续对每个问题进行独立处理。
- 输入: 上一个 Function 节点输出的 JSON 数组。
- 输出: 每个 item 包含一个问题。
-
。。。。(比较复杂中间省去一些描述)
-
Function 节点 (初始化和配置):
- 功能: 执行一些初始化操作,例如检查和创建输出目录(在 n8n 的文件系统中),以及初始化飞书表格结构(你可以使用 Feishu API 相关的 n8n 节点来实现)。
打开 Deepwiki
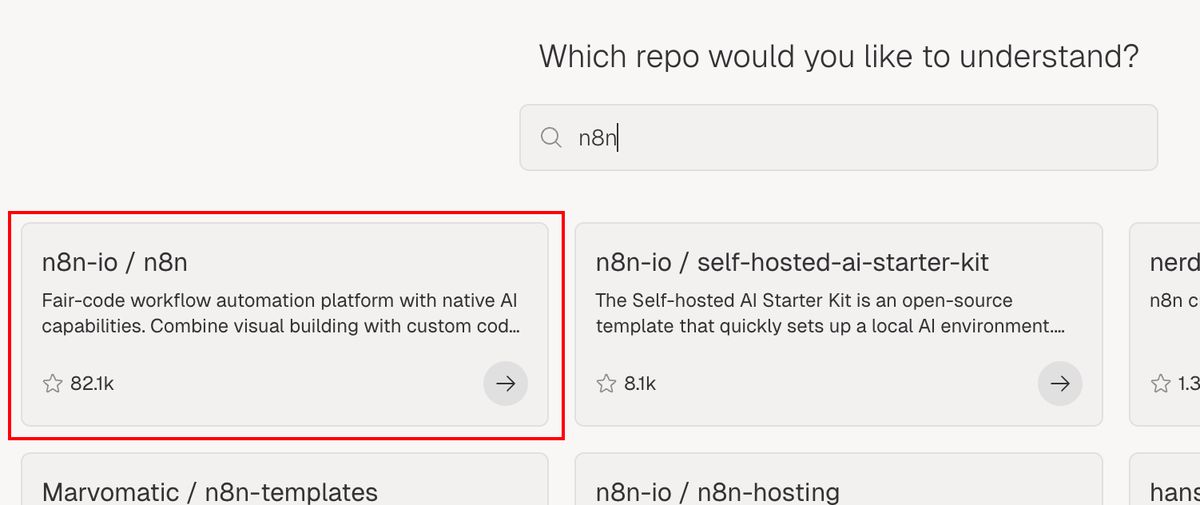
接下来,打开 Deepwiki https://deepwiki.com/
先搜索 n8n,如图,点开
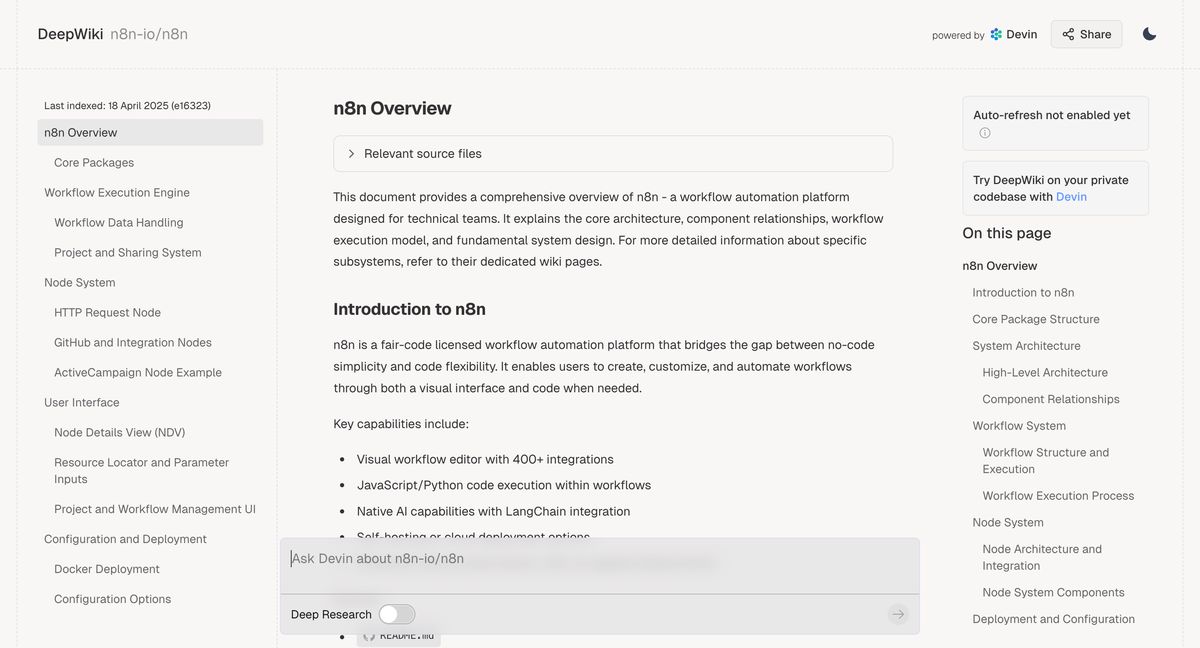
就能进入到这个项目的专题页,底下有个 Ask Devin about n8n-io/n8n,就是正常一个 AI 对话形式,在里面输入你的需求就好了,例如想修改某个功能要怎么做之类的。
DeepWiki 生成工作流 Json
把第一步得到的工作流描述扔进去对话框中。
提示词非常简单:
请根据我以下的工作流描述,生成n8n的工作流json,让我可以直接导入生成工作流:
前面生成好的流程逻辑描述
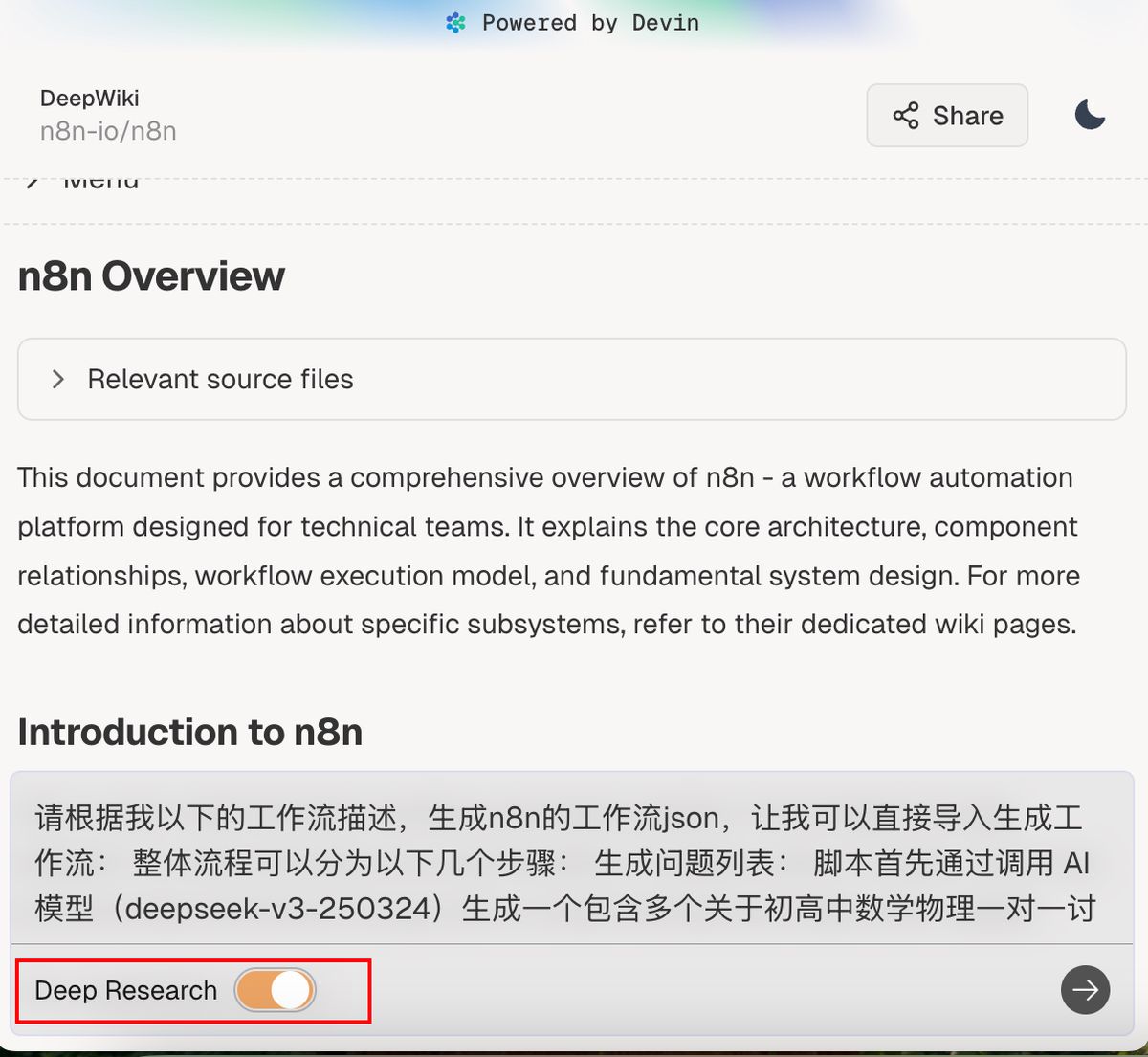
对于复杂的项目,可以直接把 Deep Research 打开,虽然等待的时间比较长,大概 5-10 分钟,但生成的结果比较可靠。
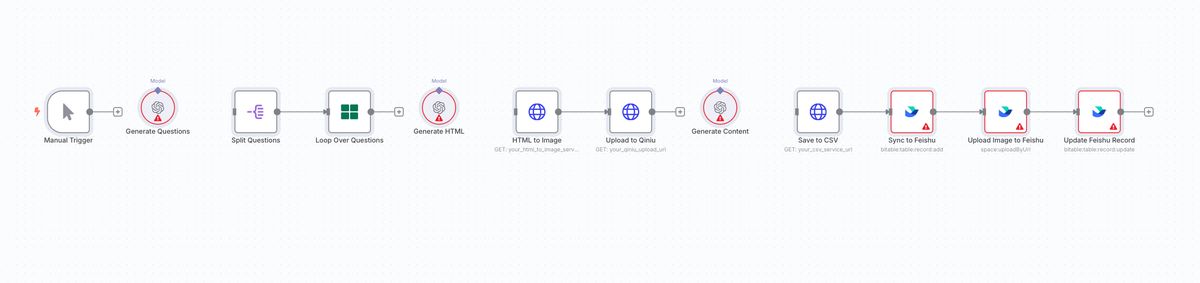
最后,我们就得到了下图这样的结果
导入 n8n
在本地新建一个 json 文件,然后把 DeepWiki 生成的 json 复制进去。
在 n8n 新建工作流,右上角 import from File,导入刚才新建好的 json 文件
见证奇迹的时刻,太牛逼了!!!
整个工作流连了起来,甚至已经做好了循环流程。接下来就是根据
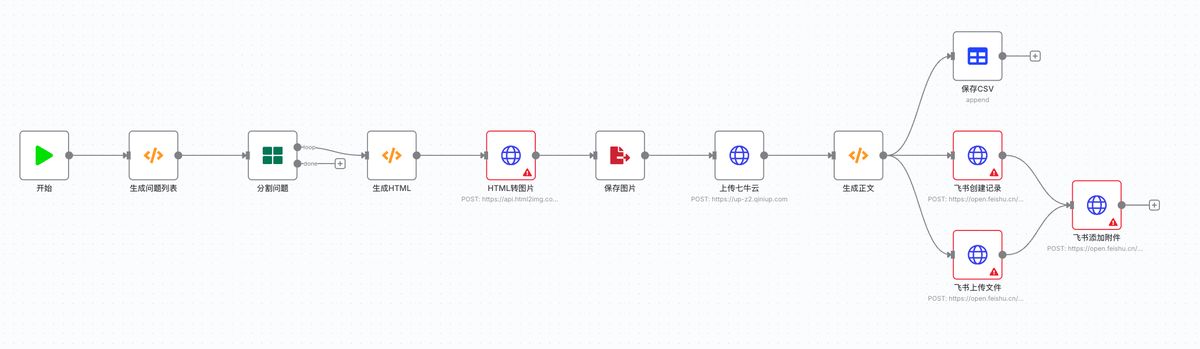
点开一些节点,能看到一些内容已经帮我们提前填好了
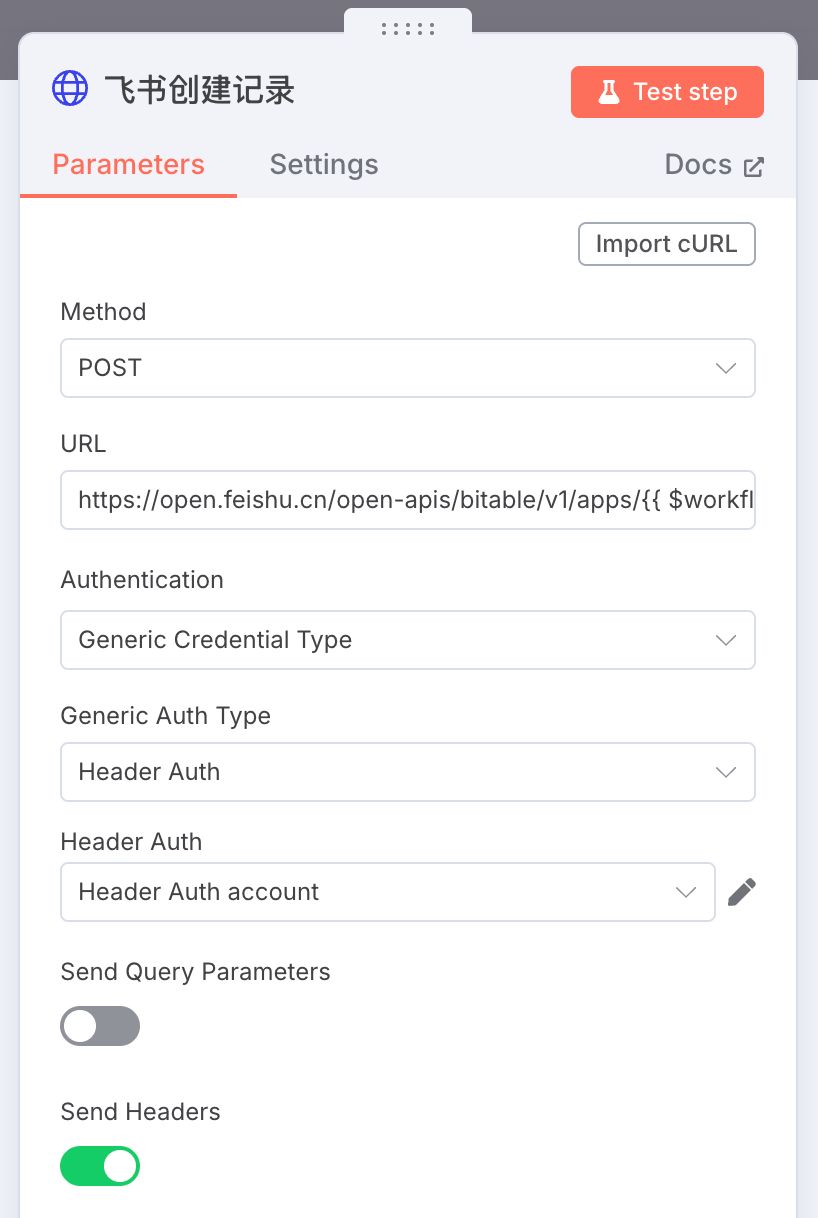
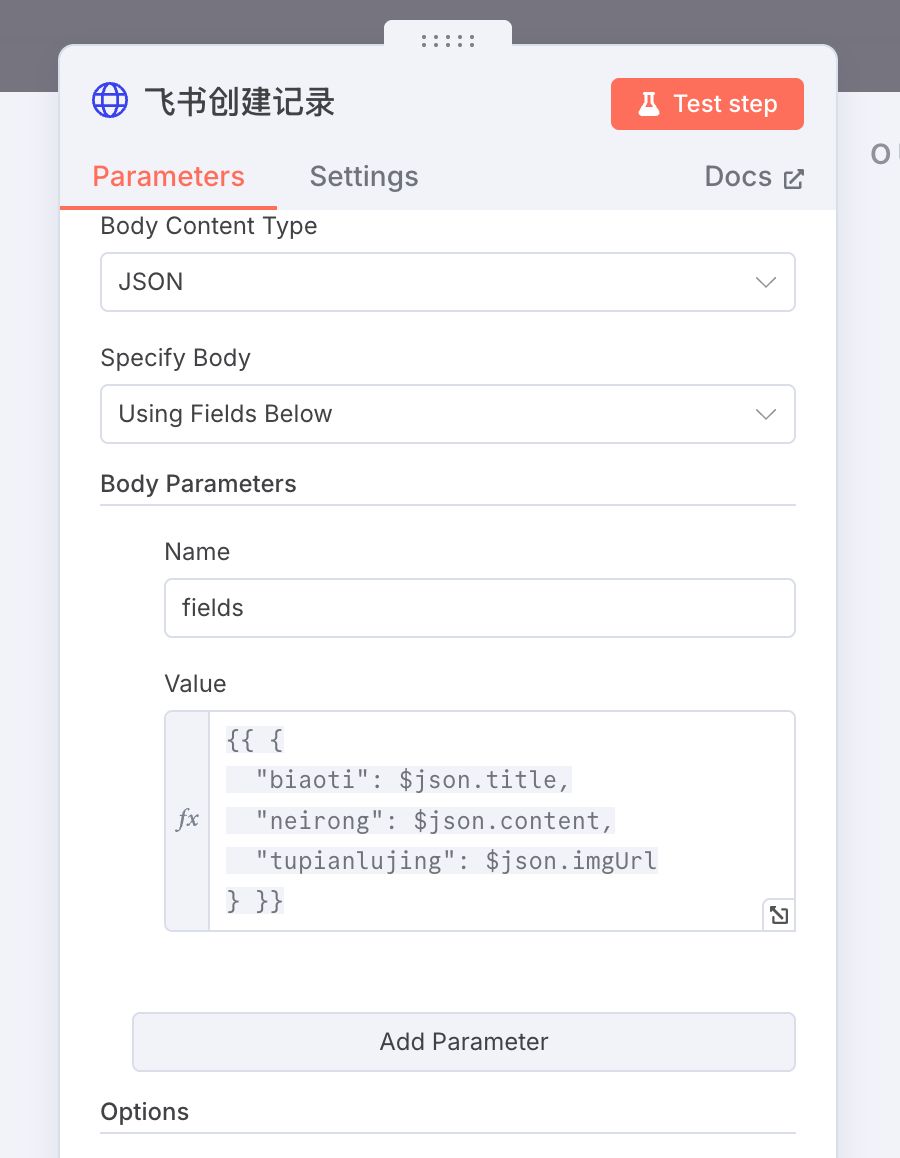
说实话,目前这个工作流不能直接跑的,好几个节点还是需要自己去设置,至少要新建密钥。
但整体来说,从你有工作流的想法,到梳理逻辑,到 n8n 落地这个过程,起码从 0 到 1 的时间能从原先的 1-3 个小时,缩短到 10 几分钟解决,效率也是很高了。
实际上还有第五步,就是发现问题,让 DeepWiki 优化
既然知道了它生成的工作流哪里有问题,就可以正常跟 AI 沟通那样让它去优化。最好能给一个已经跑通的类似工作流让它去学习优化。但我也实操了,这步效果还是比较差,还不如手动去优化掉。