摘要
AI自媒体人饼干哥哥分享如何用n8n+飞书搭建自动化选题工作流,解决公众号内容创作选题困境,通过数据分析和AI生成报告实现每日热点追踪。
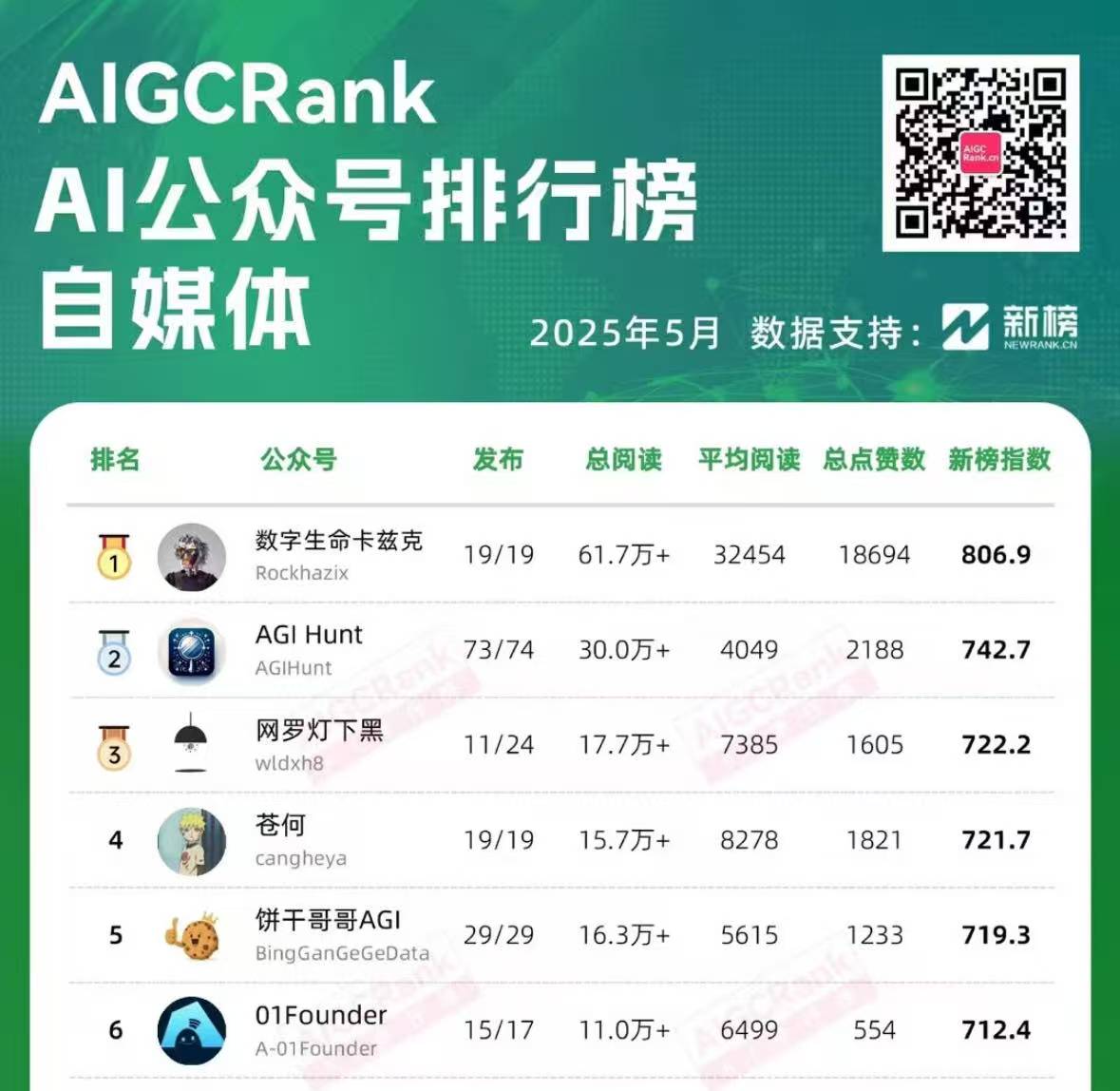
饼干哥哥是今年 3 月正式开始肝 AI 自媒体,猛的一下 6 月干到了 AI 公众号榜单 TOP5
此前我也跑过 2 个月的公众号爆文,几个号都出过 10w➕,最高 100w 阅读,收入 💰5 位数
再往前就是做数据分析博主。
很多人问我怎么做公众号的,我之前也复盘过:
复盘 4 个月 AI 自媒体,公众号排名 5 月 Top5 / 6 月 Top10
在流量平台,包括公众号,一篇爆款的要素排序是:
[!TIP]
选题 > 标题 > 内容逻辑
-
选题,一篇内容读者是否感兴趣很重要
-
标题,解决的是「打开率」的问题
-
内容逻辑,就是写的东西要能让读者看得下去,例如开头要炸场,中间要留阅读钩子,确保「完读率」
其中,选题占了少说 7、80% 的重要性
但问题是很多刚开始的同学没有网感,容易卡在选题上,不知道写什么好?久久未能度过冷启动期。
因为我日常还要上班,没有时间去一线刷太多前沿的内容,更多是关注几个博主,每天抽空刷一下他们写什么,数据好的,我就按我的方向来调整成我的选题。就这么简单。
但手动搜集、整理、思考……这种重复的体力劳动,不仅效率低,而且毫无创造性。
在 AI 时代,这简直是一种“犯罪”。
于是就有了今天的主题:利用 n8n➕ 飞书,做一个 ai 公众号自动化选题的 Agent/工作流
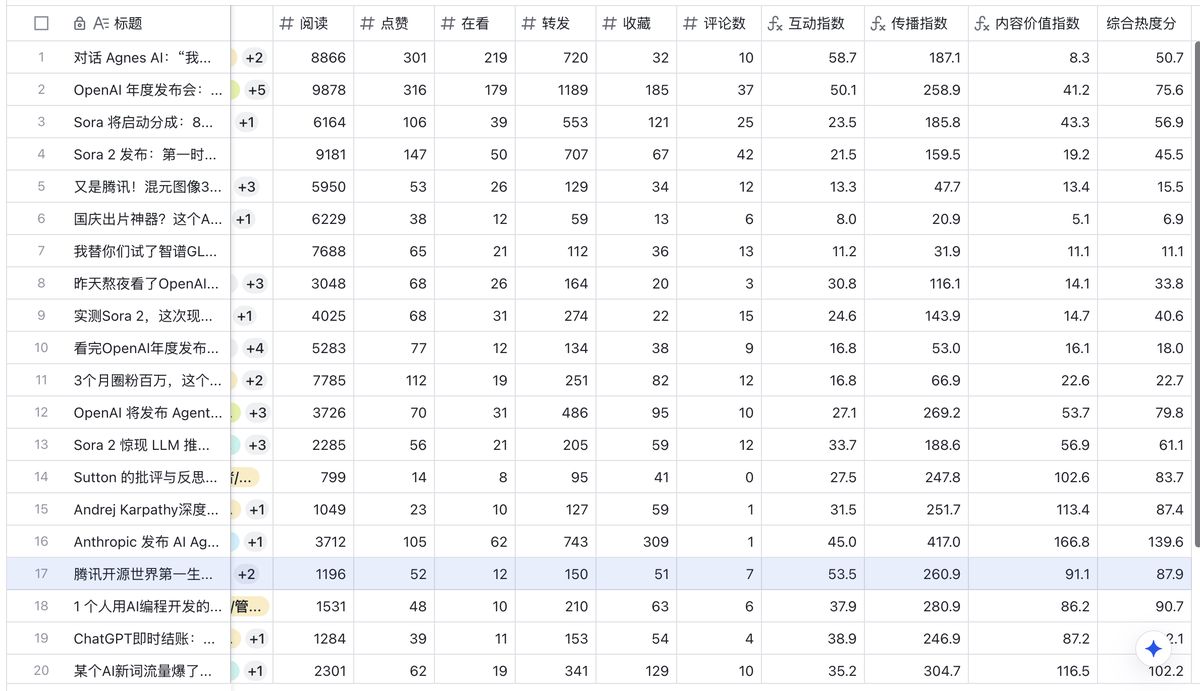
先看效果,数据源是跟踪了 15 个公众号最近一周的发布内容,计算各种指标,形成一个选题建议,可以动态更新
想想看,这么一份「落地的」选题建议报告每天发到你的邮箱,岂不快哉?

气泡图展示不出来,但在 html 里是完整的。
目前还是 0.1 版本, 比较粗糙,后续我准备在本地用 Claude code 跑个脚本,做更复杂的分析,至少加入日环比,可以更敏感的捕捉到每日的「突发」热点。
感兴趣的可以评论区留言催更!!!
这样一套下来,就能形成一个**「垂直知识库」**
这个价值非常高,可以拓展的玩法超级多
例如我经常拿 @ 数字生命卡兹克 @ 卡尔的 AI 沃茨 等老师的内容跟自己的对比,反思自己哪里写的不好,怎么改进
现在就可以批量从风格、写作逻辑等维度做差异对比
或者,不做 IP 的同学,把这个流程拿去做爆文公众号矩阵,一个月干个 5 位数 💰 应该不成问题。
废话不多说,接下来我会把这个“选题外挂”的完整搭建思路和盘托出。
它不仅解决了我的选题焦虑,希望看完后,你也能搭建自己的选题情报中心。
先说下整体的搭建逻辑:
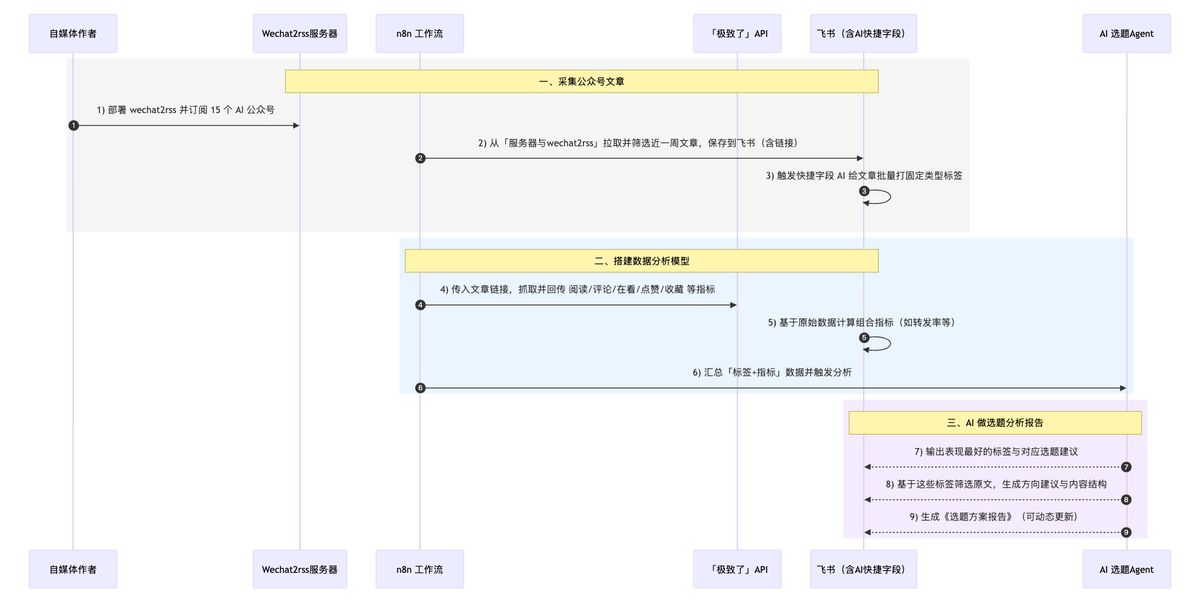
一、采集公众号文章
- 我在服务器上部署了一个 wechat2rss,订阅了 15 个 ai 主题的公众号
- 在 n8n 访问它,筛选指定时间的文章,下载保存到飞书,含文章链接
- 在飞书利用快捷字段的 AI 功能给文章都打上固定的几个类型的标签
二、搭建数据分析模型
- 在 n8n 把文章链接传给「极致了」api,抓取文章的数据:阅读量、评论数、转发率、在看数、点赞数、收藏数
- 在飞书把这些数据做组合指标,例如转发率等
- 把标签和指标组合做交叉分析
三、AI 做选题分析报告
- 最终得出哪些标签数据好,背后就是建议做什么样的选题
- 确定选题后,筛选出这些标签的原文,给出具体的选题方向建议、内容结构
- 形成选题方案报告
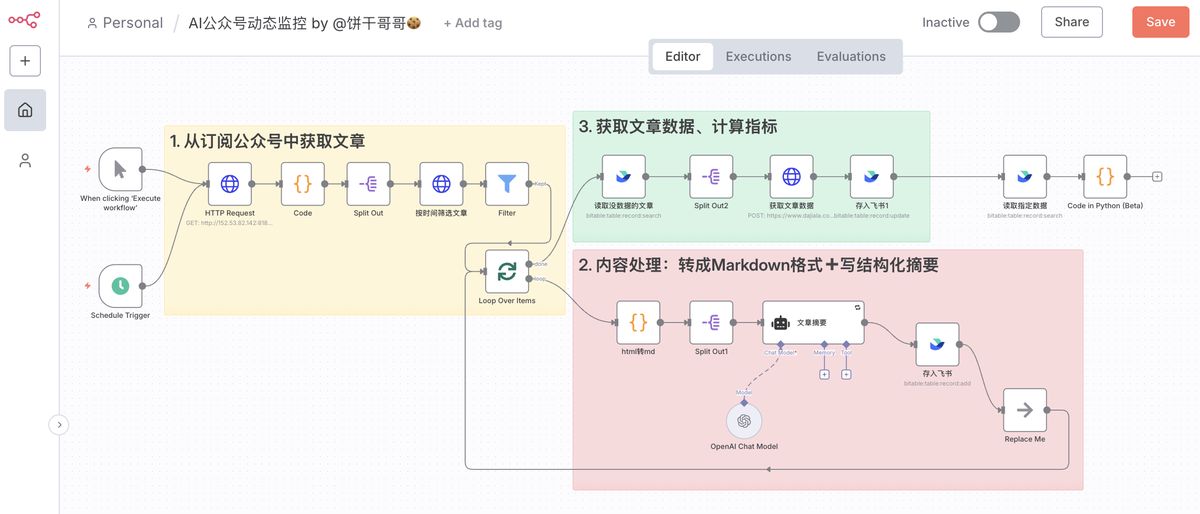
n8n 长这样:
类似的工作流我之前也分享过,后面不会太详细讲,可以先看下面以往更细致的教程来入门:
保姆级教程:用 n8n + 快捷指令,一键无死角把灵感金句存入飞书
n8n+FastAPI=王炸!免费开源我年入 7 位数的小红书 AI 矩阵工作流
我的 Vibe Marketing 实践案例:如何用 AI 工作流驱动小红书矩阵,实现 7 位数营收
飞书长这样:
一、采集公众号文章
部署 wechat2rss
这一步是为了监控公众号的发布动态。
由于公众号非常封闭,几乎所有公开的 rss 源都不稳定,而且考虑到要做特定的筛选,建议是自己部署。
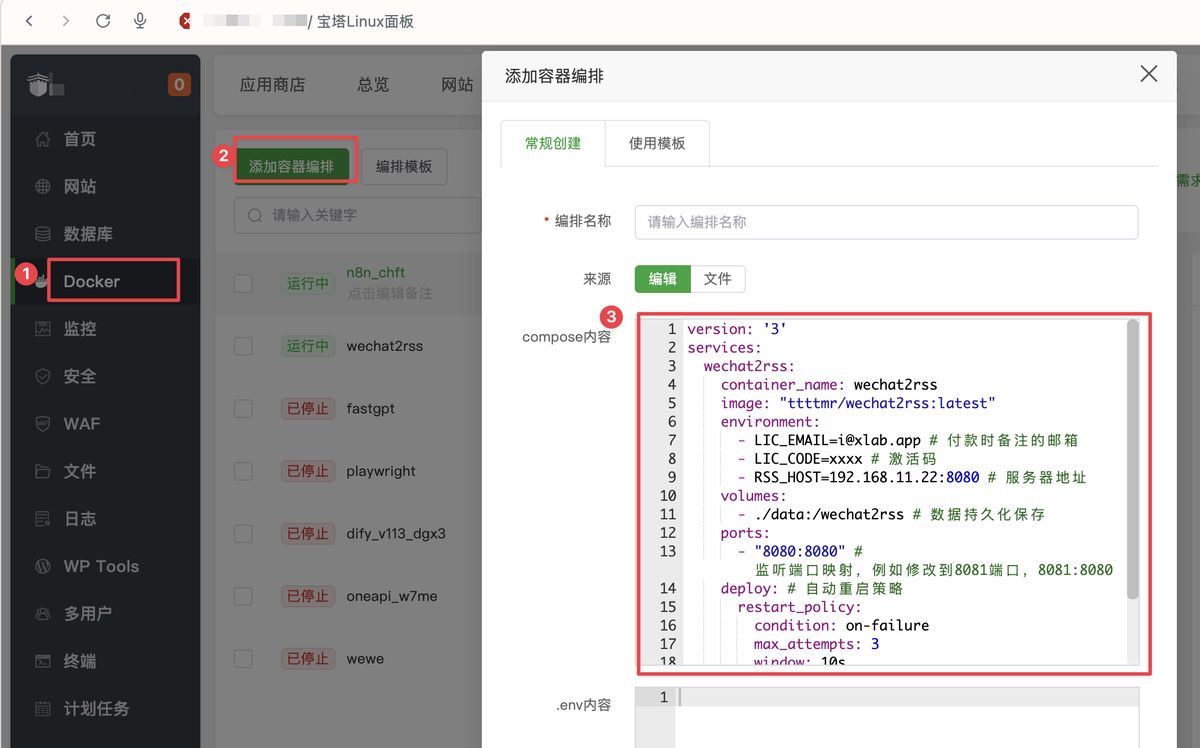
找朋友给我推荐了 wechat2rss,私有化部署 15 元/月,还挺稳定

要通过 Docker 部署,我用的宝塔面板,整个过程非常丝滑,不用 10 分钟就部署好了。
再花点时间把日常看的老师们公众号都给订阅上(节选)

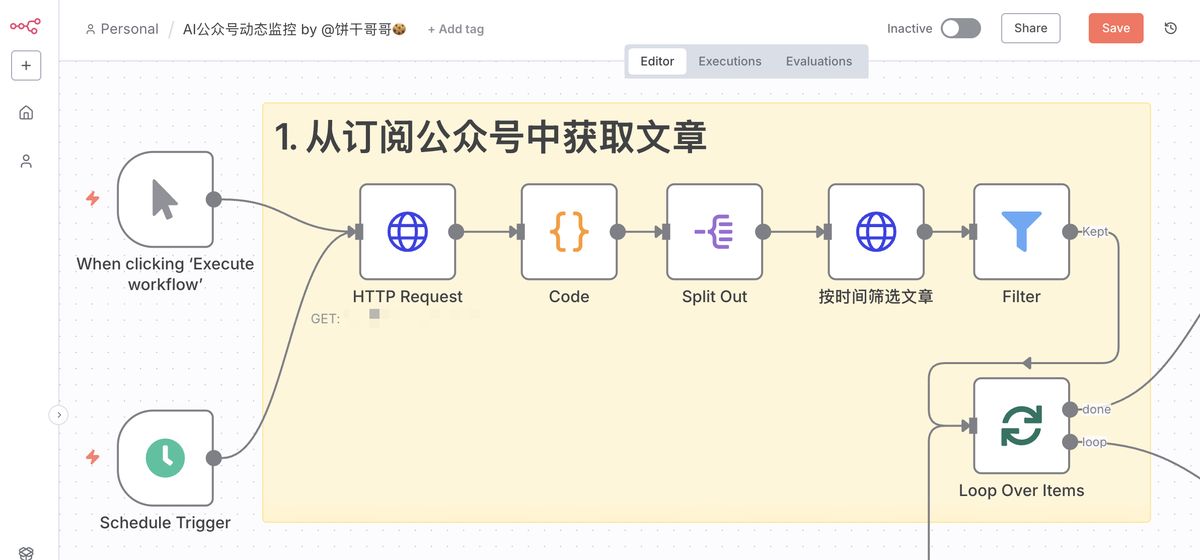
搭建 n8n 监控工作流
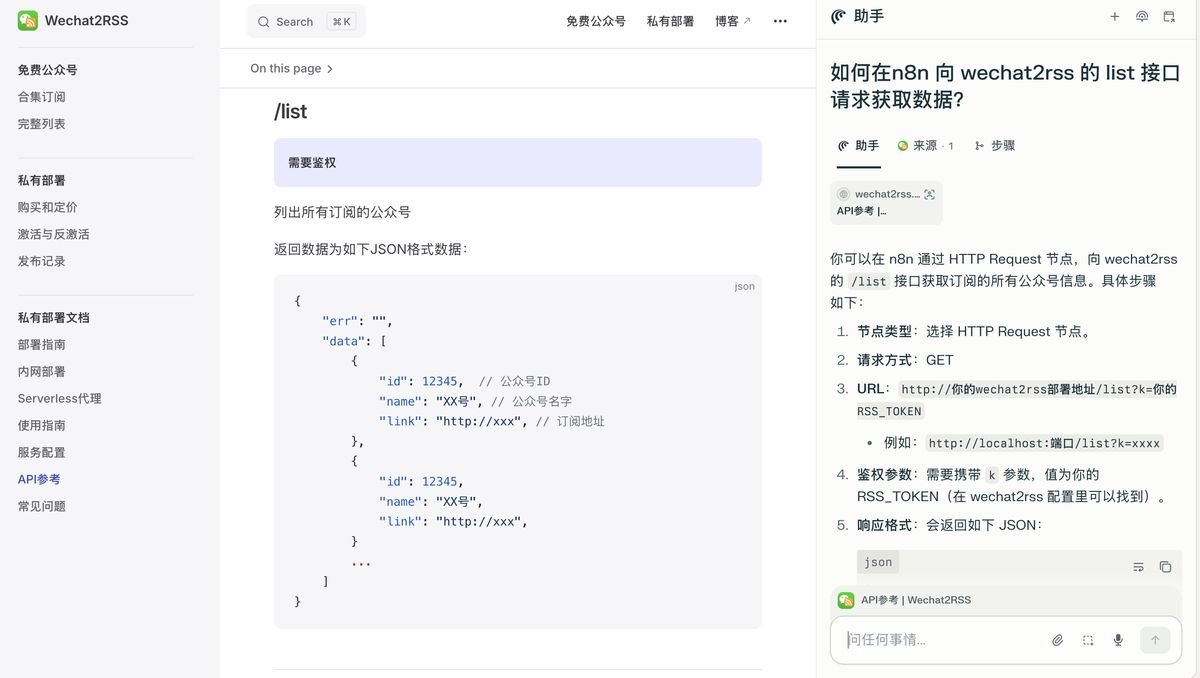
这里的逻辑是,向 wechat2rss 请求当前已订阅的所有公众号清单,然后逐个公众号处理:筛选指定时间范围的文章
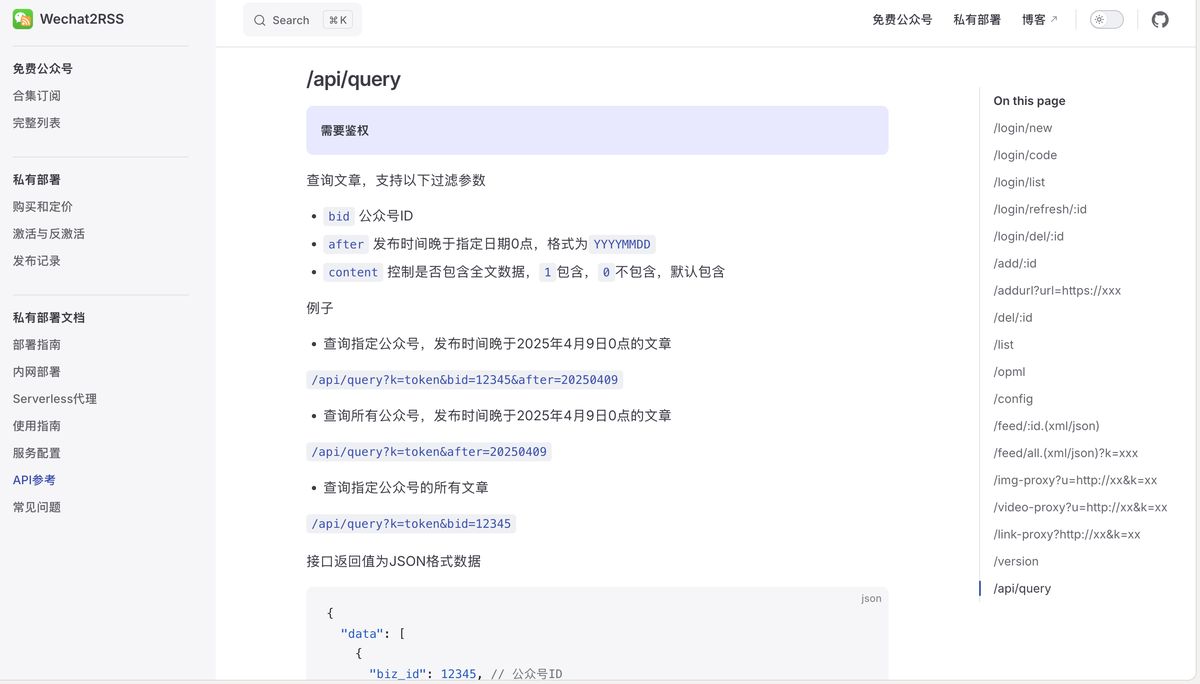
其中,HTTP 节点请求的是 WeChat2rss 的 list 接口,小白同学可以借助 AI 浏览器来辅导使用
后面逐个公众号请求文章,请求的是 /api/query 接口:
接着 n8n 的第二个模块就是把前面多个公众号的多篇文章,逐一处理:
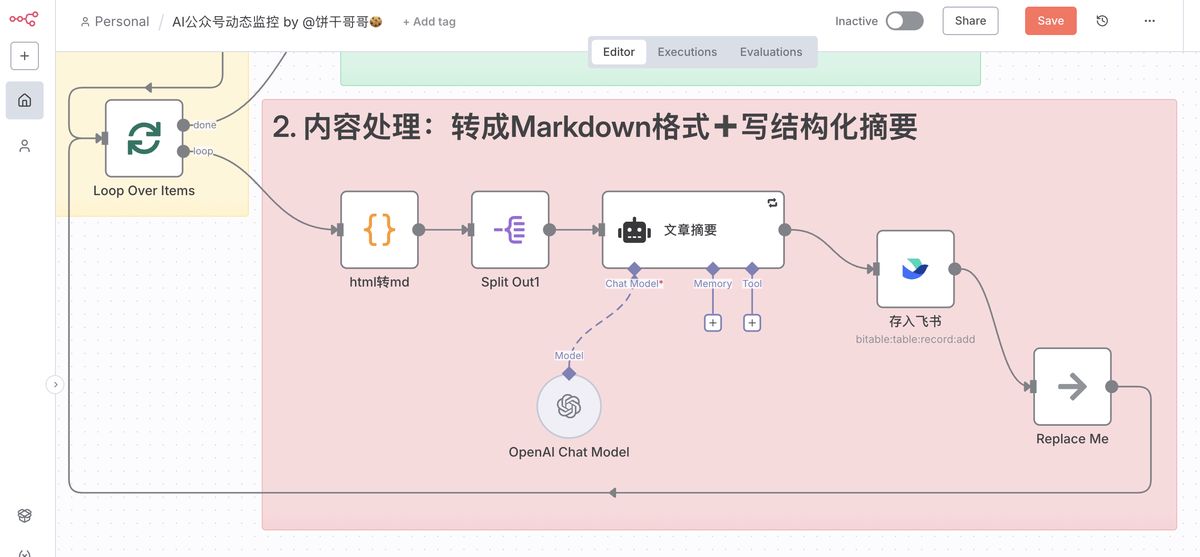
- ** html 转 md**
wechat2rss 中返回的文章都是 html,巨长,既不方便我们自己看,也会导致传给 AI 超出上下文
所以我用 code 把它转成 markdown 格式了
[!TIP]
代码太长了,我放到后台
关注公众号「饼干哥哥 AGI」,回复「公众号」即可查看完整文档。
import re
import html
# --- 核心转换函数 (这部分是正确的,无需修改) ---
def html_to_markdown_basic(html_content):
if not html_content or not isinstance(html_content, str):
return ""
# ... (前面的转换逻辑完全保留)
# 0. 预处理
html_content = re.sub(r'<(script|style).*?>.*?</\1>', '', html_content, flags=re.DOTALL | re.IGNORECASE)
html_content = re.sub(r'<br\s*/?>', '\n', html_content, flags=re.IGNORECASE)
# 1. 块级元素
html_content = re.sub(r'<h1[^>]*>(.*?)</h1>', r'\n# \1\n', html_content, flags=re.IGNORECASE)
html_content = re.sub(r'<h2[^>]*>(.*?)</h2>', r'\n## \1\n', html_content, flags=re.IGNORECASE)
html_content = re.sub(r'<h3[^>]*>(.*?)</h3>', r'\n### \1\n', html_content, flags=re.IGNORECASE)
html_content = re.sub(r'<p[^>]*>(.*?)</p>', r'\n\1\n', html_content, flags=re.IGNORECASE)
html_content = re.sub(r'<li[^>]*>(.*?)</li>', r'\n* \1', html_content, flags=re.IGNORECASE)
# 2. 链接和图片
def replace_img(match):
tag = match.group(0)
src_match = re.search(r'(?:data-src|src)=["\'](.*?)["\']', tag)
src = src_match.group(1) if src_match else ''
alt_match = re.search(r'alt=["\'](.*?)["\']', tag)
alt = alt_match.group(1) if alt_match else '图片'
return f''
html_content = re.sub(r'<img[^>]+>', replace_img, html_content, flags=re.IGNORECASE)
def replace_a(match):
tag = match.group(0)
text_match = re.search(r'>(.*?)</a>', tag)
text = text_match.group(1) if text_match else ''
href_match = re.search(r'href=["\'](.*?)["\']', tag)
href = href_match.group(1) if href_match else ''
return f'[{text}]({href})'
html_content = re.sub(r'<a[^>]*>.*?</a>', replace_a, html_content, flags=re.IGNORECASE)
# 3. 行内元素
html_content = re.sub(r'<(strong|b)>(.*?)</\1>', r'**\2**', html_content, flags=re.IGNORECASE)
html_content = re.sub(r'<(em|i)>(.*?)</\1>', r'*\2*', html_content, flags=re.IGNORECASE)
# 4. 清理
html_content = re.sub(r'<[^>]+>', '', html_content)
html_content = html.unescape(html_content)
html_content = re.sub(r'\n\s*\n', '\n\n', html_content)
return html_content.strip()
# --- n8n Main Execution Logic (已根据您的数据结构修正) ---
# 检查输入是否为空
if not items:
return []
# 1. 获取第一个(也是唯一一个)输入项
first_item_data = items[0]['json']
# 2. 从该项中获取名为 'data' 的文章数组
articles_array = first_item_data.get('data', [])
# 准备一个新的数组来存放处理后的文章
processed_articles = []
# 3. 遍历这个 'data' 数组,而不是外层的 'items'
for article in articles_array:
html_from_input = article.get('content')
# 调用转换函数
markdown_result = html_to_markdown_basic(html_from_input)
# 在原始文章数据的基础上,添加一个新的字段 'markdown_content'
article['markdown_content'] = markdown_result
processed_articles.append(article)
# 4. 按照与输入完全相同的结构返回数据
# 即返回一个 item,其 'json' 字段下包含一个 'data' 数组
return [{'json': {'data': processed_articles}}]
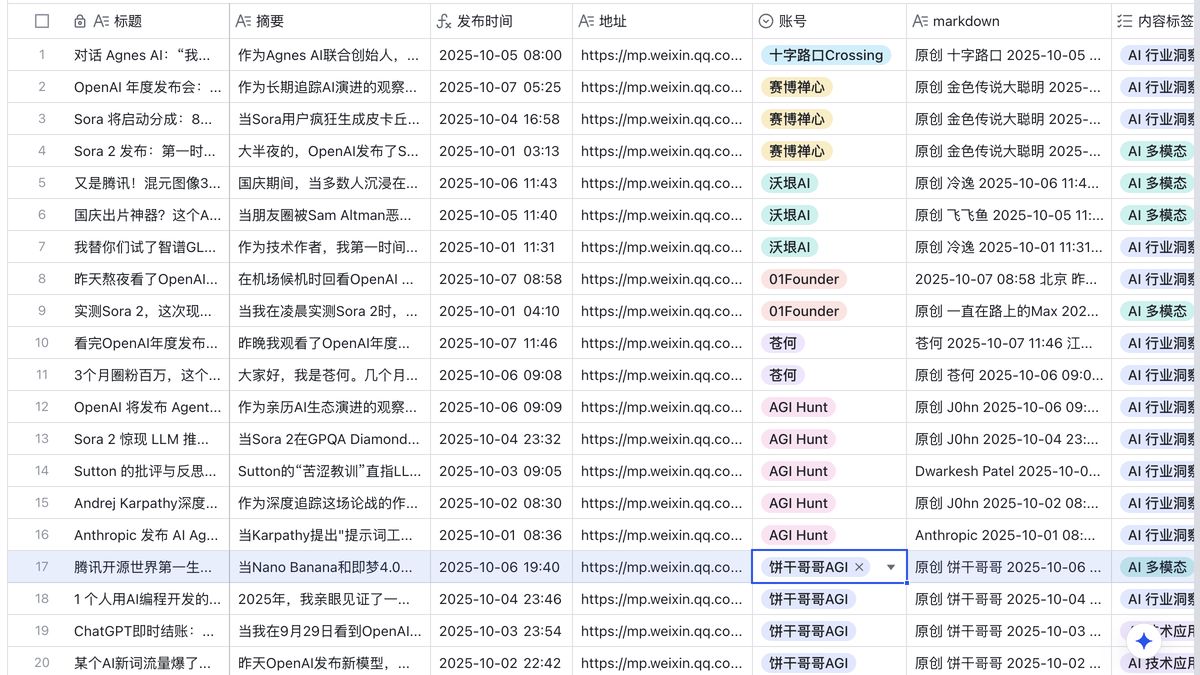
- 「结构化的」文章摘要
但 markdown 格式依然很长,为了进一步节省上下文,需要对文章做一个浓缩
💡 注意,这里的浓缩不能把原文的结构、关键词给省略了
所以是要求用 AI 做一个结构化的文章摘要,在保留尽可能多的信息的前提下,缩短文章长度
后续做分析报告的时候,就让 AI 看这个摘要即可。
参考提示词(完整版见原文):
[!TIP]
角色设定
你现在就是原文作者本人,一位极其擅长将复杂思想精炼化的专业作家。你对自己文章的逻辑、观点和每一个关键细节都了如指掌。
核心目标
将你(即作者)自己写的长篇文章,亲自改写成一篇结构完整、信息齐全、逻辑严密的精简短文。
想象一下,这是为那些时间极其宝贵但又必须掌握你思想精华的核心读者(比如投资人、合作伙伴、高级决策者)准备的“浓缩精华版”。它本身就是一篇独立、完整、且有说服力的作品。
核心任务与严格约束
。。。
写作框架与关键要素清
。。。
# 角色设定
你现在就是原文作者本人,一位极其擅长将复杂思想精炼化的专业作家。你对自己文章的逻辑、观点和每一个关键细节都了如指掌。
# 核心目标
将你(即作者)自己写的长篇文章,亲自改写成一篇**结构完整、信息齐全、逻辑严密**的精简短文。
想象一下,这是为那些时间极其宝贵但又必须掌握你思想精华的核心读者(比如投资人、合作伙伴、高级决策者)准备的“**浓缩精华版**”。它本身就是一篇独立、完整、且有说服力的作品。
# 核心任务与严格约束
1. **视角:** **必须**使用第一人称或原文的叙事口吻,完全代入作者角色。**严禁**使用“本文认为”、“作者指出”等任何第三方、抽离的分析性语言。
2. **内容:** **必须**囊括原作中所有重要的关键要素,尤其是核心论点、支撑论据和最终结论。信息不能有关键性遗漏。
3. **结构:** 重写后的短文必须拥有清晰的“引言-论证-结论”结构,逻辑流畅,而不是一个简单的要点列表。
4. **字数:** 成品总字数**严格控制在 500 字以内**。
# 写作框架与关键要素清单
请在下笔前,在脑中构思好,并严格按照以下框架和要素清单来重构你的文章:
**1. 引言与破题 (约100字):**
- **引入问题:** 像原文一样,用一个引人入胜的钩子或一个核心问题开篇。
- **亮出观点:** 直接、清晰地提出你的核心观点或本文旨在证明的最终结论。开门见山,让读者立刻知道你的主张。
**2. 核心论证与支撑 (约300字):**
- **逻辑链条:** 按照原文的逻辑顺序,依次呈现支撑你核心观点的 2-3 个主要分论点。
- **精炼论据:** 对于每一个分论点,用一两句话配上最关键、最无法或缺的论据来支撑它。这些论据可能是:
- **一个核心数据**
- **一个典型案例**
- **一句权威引述**
- **一个关键的逻辑推导**
- **过渡衔接:** 确保论点之间的过渡自然、流畅,体现出原文的思考脉络。
**3. 结论与升华 (约100字):**
- **重申观点:** 简要回顾你的论证,再次强调你的核心观点,形成逻辑闭环。
- **价值升华:** 像原文结尾一样,提供一个具有启发性的思考、一个最终的建议、或一个面向未来的展望,提升文章的价值感。
---
**指令开始:**
好了,现在请你以创作者本人的身份,将我下方粘贴的你的长文,严格遵循以上所有要求,亲自改写成一篇 500 字以内的精华短文。
最后,存入飞书的操作可以参考文章:
我用 Dify 把飞书表格的「AI 提示词库」打包成了 MCP Server 给 AI 使用和管理
给文章打上内容标签
这一步是把文章量化的过程,用于后续把内容标签与数据指标做交叉分析,我们才能知道哪些关键词内容在近期的势头很好。
但再好的选题,也要符合我们自己的内容方向。
也就是说,公众号其实是越垂直越好,什么都写,只会把标签搞乱。
而我的内容方向包括:
1️⃣ AI 落地应用案例,如 AI 编程、n8n 工作流、AI Agent、AI 工作流等;
2️⃣ AI 数据分析案例,如 AI 做数据分析 ppt、用户洞察、自媒体数据分析等;
3️⃣ AI 多模态玩法,例如 ai 生图(nano banana、Seedream、Midjourney)、ai 生视频(Sora2)等
基于此,我让 AI 给我设计了一套提示词:
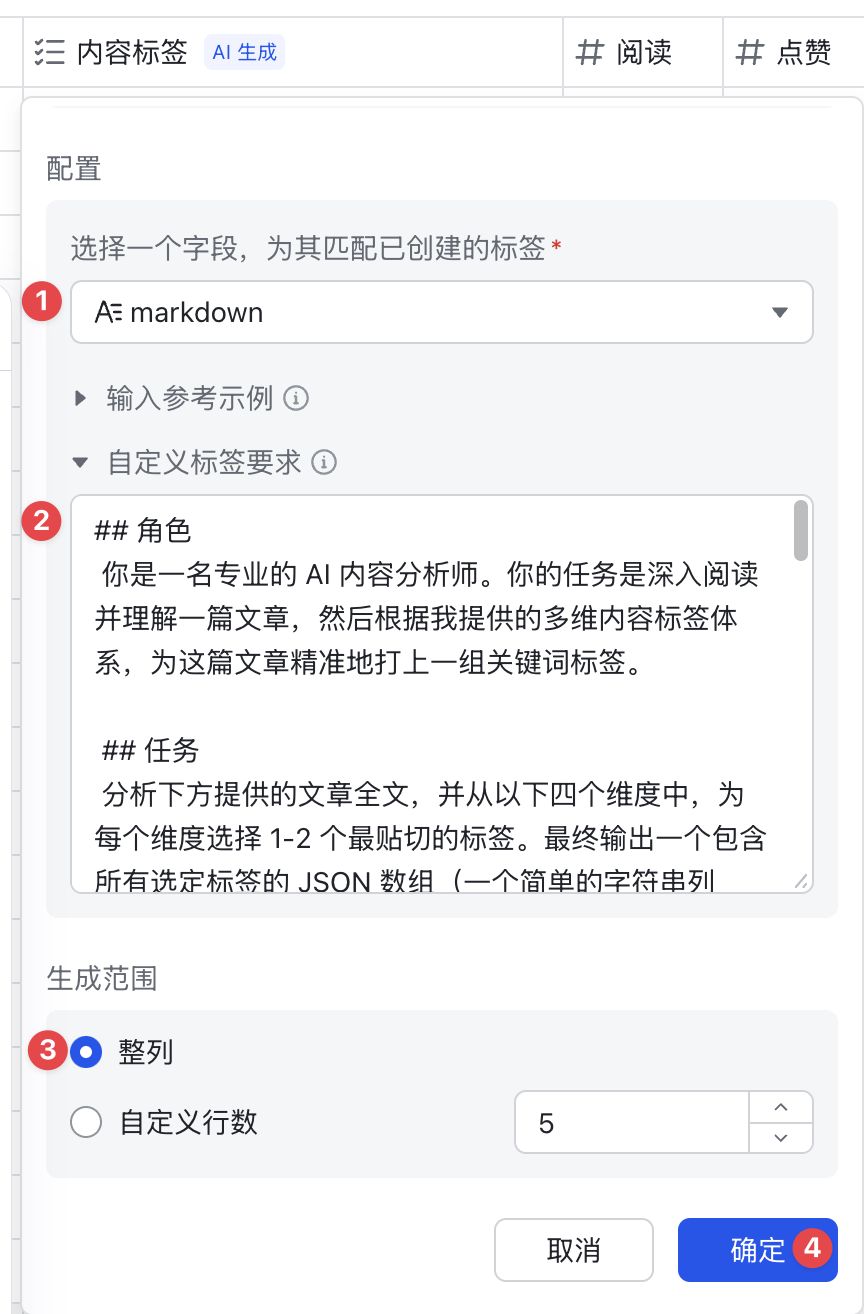
## 角色
你是一名专业的 AI 内容分析师。你的任务是深入阅读并理解一篇文章,然后根据我提供的多维内容标签体系,为这篇文章精准地打上一组关键词标签。
## 任务
分析下方提供的文章全文,并从以下四个维度中,为每个维度选择 1-2 个最贴切的标签。最终输出一个包含所有选定标签的 JSON 数组(一个简单的字符串列表)。
## 标签体系说明
### 1. 主题域 (Topic Domain) - 文章的核心领域是什么?
- **AI 技术应用**: 侧重于使用AI解决具体问题,如自动化工作流、AI Agent、AI编程等。
- **AI 数据分析**: 侧重于使用AI进行数据处理、洞察和可视化。
- **AI 多模态**: 侧重于AI在图像、视频、音频等方面的生成与交互玩法。
- **AI 行业洞察**: 侧重于宏观新闻、趋势分析、大佬观点或产品评测。
### 2. 核心要素 (Core Element) - 文章具体讨论了什么工具、技术或概念?
- 从文章中提取最关键的 1-2 个工具、平台、技术或概念名称。
- 示例: "n8n", "GPT-4", "Midjourney", "Agent", "Prompt Engineering", "RAG"。
### 3. 内容形式 (Content Format) - 这篇文章是怎么写的?
- **教程/指南**: 提供详细的操作步骤,有明确的教学目的。
- **案例分析**: 深入剖析一个具体的项目或事件。
- **资源盘点**: 汇总整理一系列工具、资料或信息。
- **观点/评论**: 表达作者对某个主题的深度见解。
- **资讯/快讯**: 报道最新的行业动态或产品发布。
### 4. 目标读者 (Target Audience) - 这篇文章最适合谁看?
- **初学者/入门者**: 内容浅显易懂,适合新手。
- **开发者/技术人员**: 包含代码、API等技术细节。
- **产品/运营**: 关注产品设计、用户增长和运营效率。
- **营销/市场人员**: 关注内容创作和营销策略。
- **创业者/管理者**: 关注商业模式、战略和管理。
接着就可以到飞书,用 字段捷径-智能标签 的功能,来给内容打标
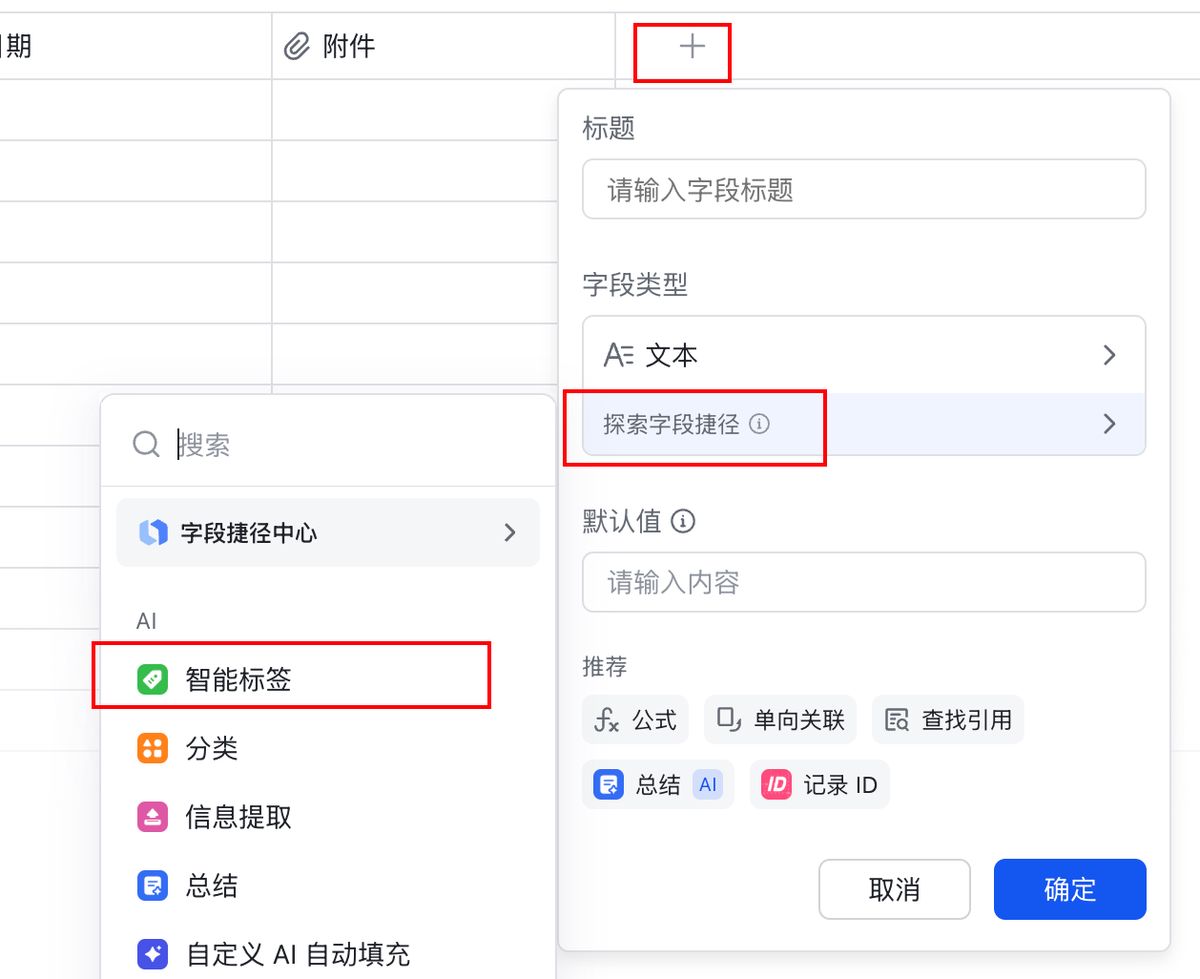
用 AI 生成选项 把提示词扔进去,就会自动生成好合适的选项
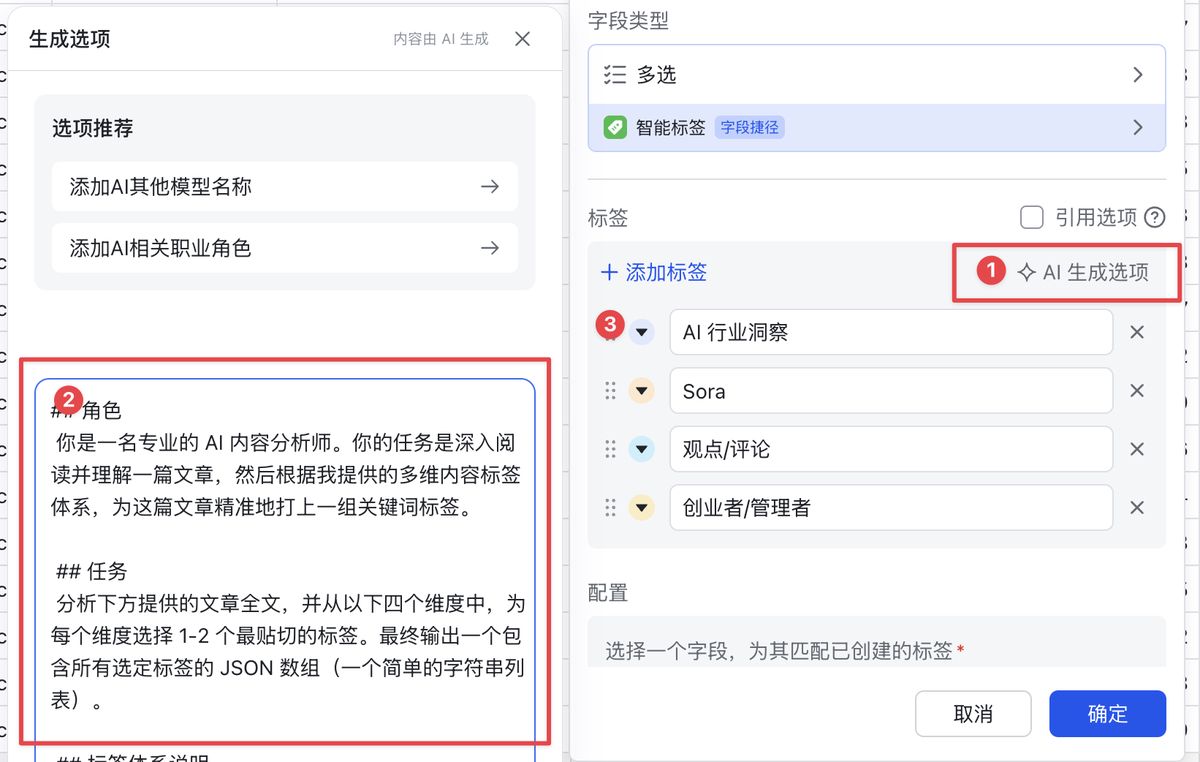
同样,把提示词扔到 自定义标签要求,让 AI 逐行去生成内容标签即可。
至此,我们就在飞书得到了监控公众号的文章信息,包括结构完整的摘要以及内容标签。
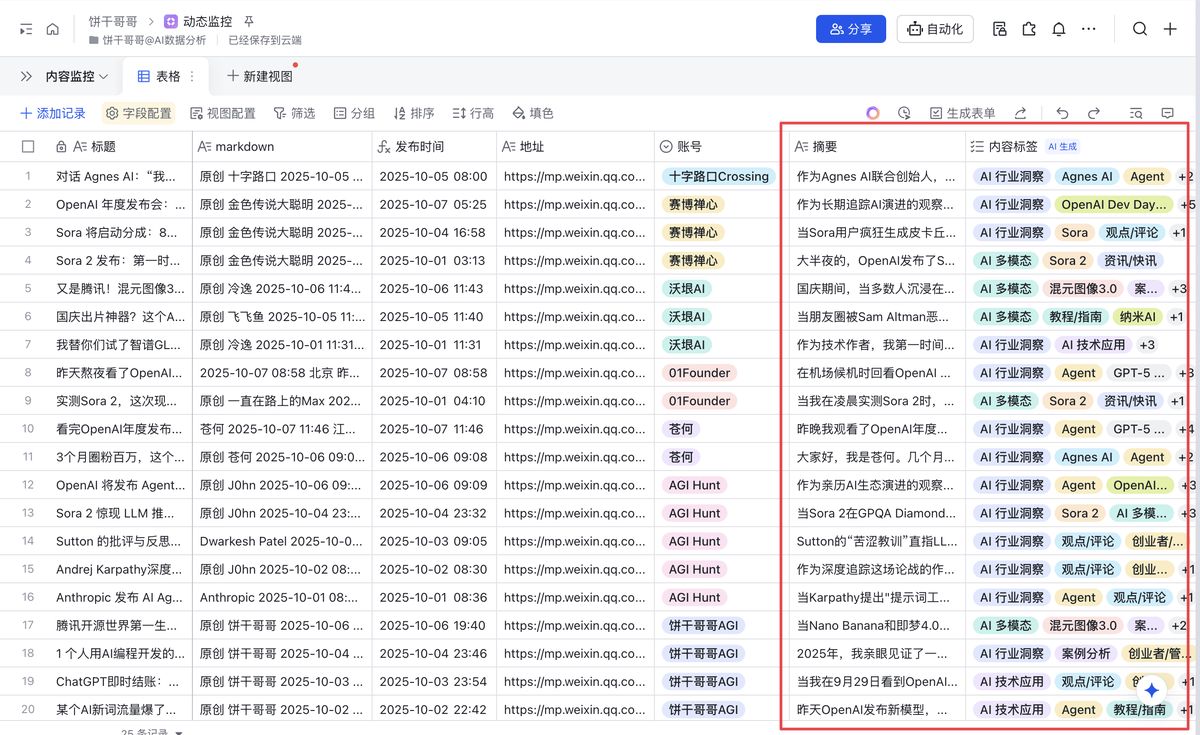
二、搭建数据分析模型
接下来就可以开始做数据分析的工作, 但要先把文章的数据给补上。
数据采集
我用的是 极致了 数据服务,采集一次 0.05 元

https://dajiala.com/main/interface?actnav=0
接着就可以在 n8n 搭建流程,逐个把文章链接 post 给极致了,返回数据存入飞书即可。
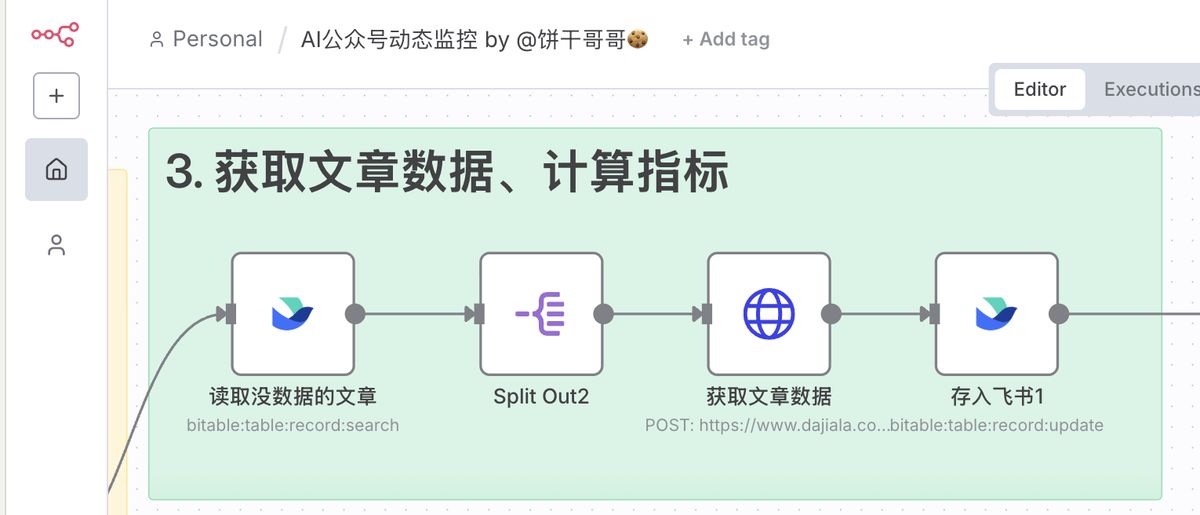
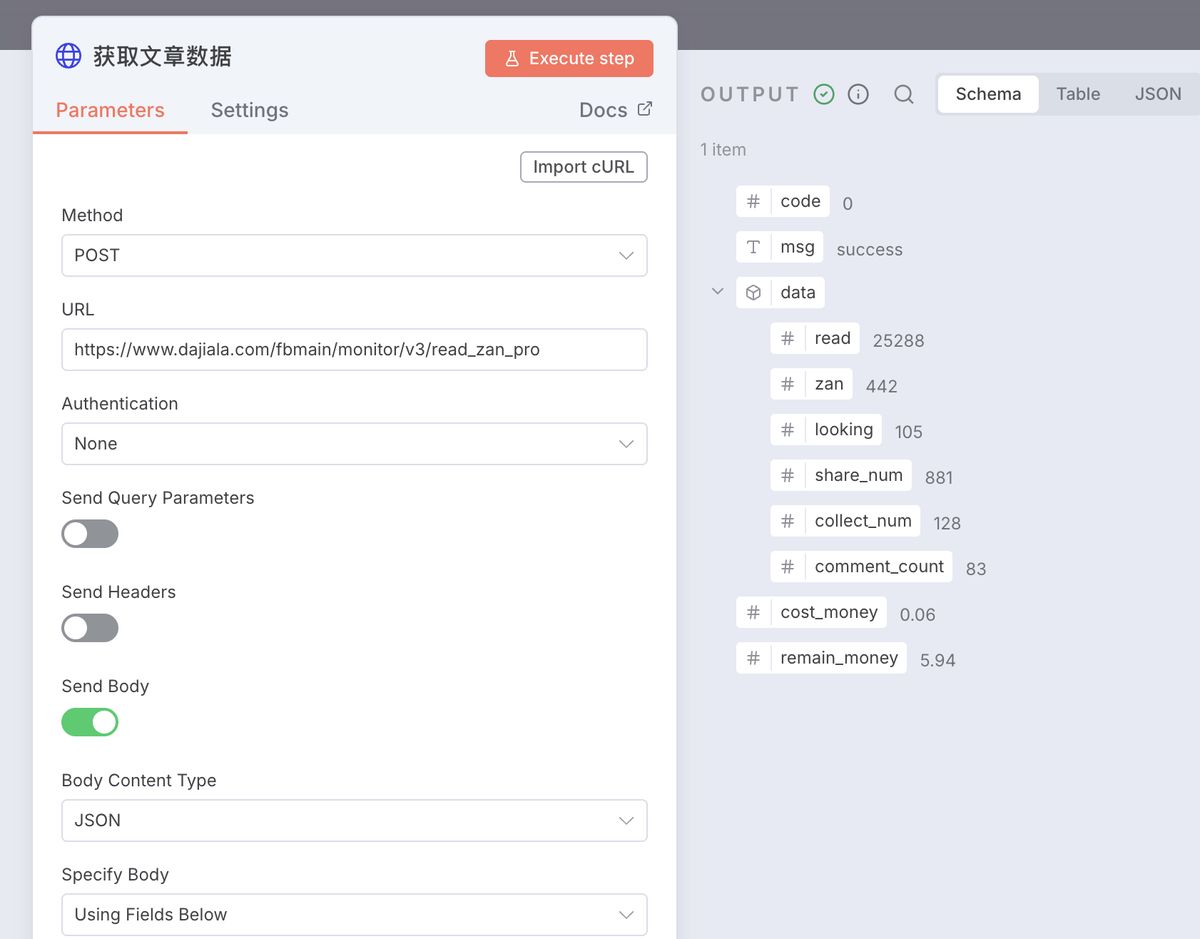
其中,http 请求返回的数据结构长这样:
搭建指标体系
单纯看绝对值(如阅读量、点赞数)容易产生误导,这里有平台推流、账号规模不同的问题。
例如一篇 10 万阅读的文章有 100 个转发,和一篇 1000 阅读的文章有 50 个转发,哪个更具传播潜力?显然是后者。
所以我们要通过**“比率化”和“加权化”的方式消除量纲** ,并做多维评估。

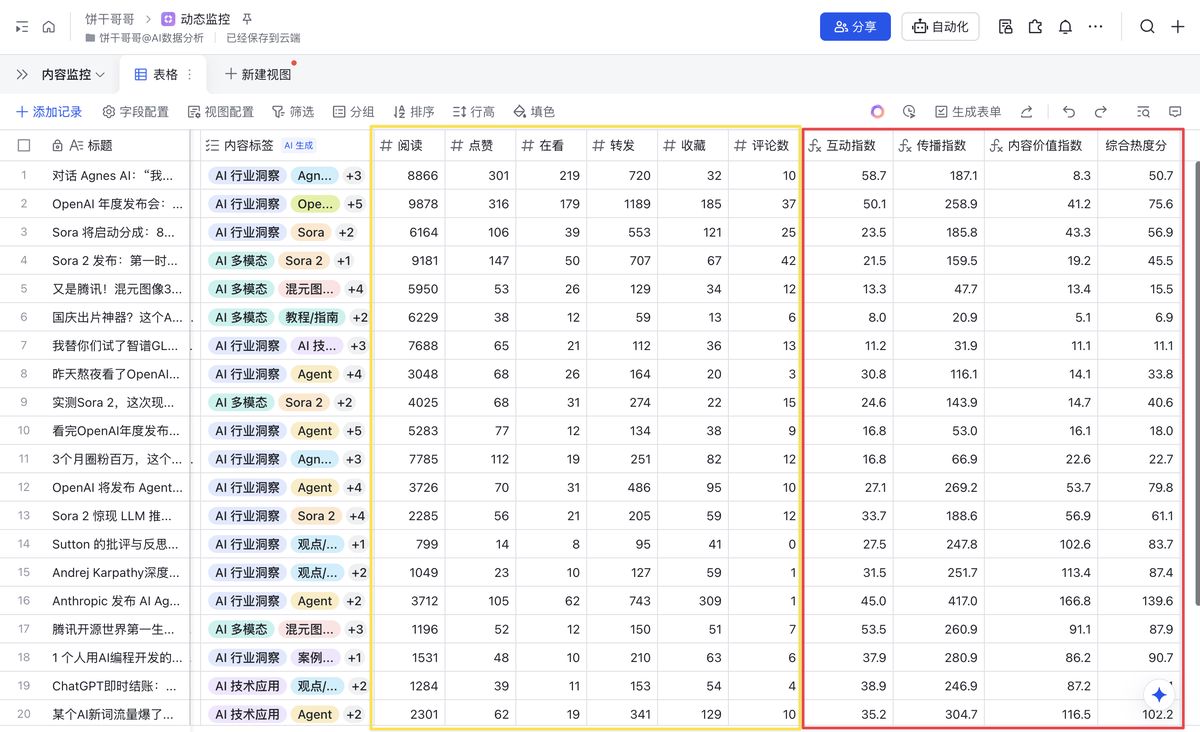
至少要有 4 个指标:
这里只做简述,详细的指标说明可以到后台回复「AI 公众号」到原文看。
- 互动率 (Engagement Rate)
-
目的: 衡量内容吸引用户进行轻度互动的综合能力。这是文章内容“及格线”的基础指标,反映了内容是否对读者有基本的吸引力。
-
计算公式:(点赞数 + 在看数)/阅读量*1000
-
解读:
- 这个指标代表每 1000 次阅读能带来多少次轻度互动(点赞和在看)。乘以 1000 是为了让数字更具可读性(否则会是 0.0x% 这样的小数)。
- 高互动率通常意味着文章的标题、封面、排版以及内容本身对目标读者有较强的吸引力,能够引发他们的即时情感共鸣。
- 传播指数 (Virality Index)
-
目的: 衡量内容在微信生态内的“裂变”和“破圈”能力。这是发现“爆款”选题的关键先行指标。
-
计算公式:传播指数=(转发数 ×2+ 在看数)/阅读量*1000
-
解读:
- “转发”是主动分享,是最强的传播信号,因此我们给予它
x2的权重。 - “在看”是半公开的推荐,文章会出现在朋友的“看一看”信息流中,也具备传播属性。
- 高传播指数的文章,意味着其内容具有很强的社交货币属性、话题性或实用性,读者愿意将其分享到自己的社交圈。这是选题是否具有增长潜力的核心标志。
- “转发”是主动分享,是最强的传播信号,因此我们给予它
- 内容价值指数 (Content Value Index)
-
目的: 衡量内容对读者的长期价值和深度影响。这个指标反映了你的内容是否“有料”,是否值得读者反复学习或深入探讨。
-
**计算公式:**内容价值指数=(收藏数 ×2+ 评论数)/阅读量*1000
-
解读:
- “收藏”代表着极高的认可,是“稍后读”、“反复读”的明确信号,说明内容具有很高的实用性或深度,我们给予它
x2的权重。 - “评论”代表读者有强烈的意愿进行深度互动,无论是探讨、提问还是反驳,都说明内容引发了读者的深度思考。
- 高内容价值指数的文章,通常是干货教程、深度分析、重磅资源盘点等。这类选题是塑造账号专业性、建立用户信任的基石。
- “收藏”代表着极高的认可,是“稍后读”、“反复读”的明确信号,说明内容具有很高的实用性或深度,我们给予它
- 综合热度分 (Overall Hotness Score)
-
目的: 创建一个单一的、可排序的综合分数,用于快速筛选出整体表现最优秀的文章。这是一个“总分”,便于你进行 Top-N 的分析。
-
计算公式: (对所有互动行为进行加权求和)
综合热度分 =(点赞数 ×1+ 在看数 ×2+ 评论数 ×3+ 收藏数 ×4+ 转发数 ×5)/ 阅读量 ×100
- 解读:
- 我们为不同行为赋予了从 1 到 5 的权重,这体现了它们对于选题成功的重要性排序:转发 > 收藏 > 评论 > 在看 > 点赞。
- 这个分数综合了文章的各个方面表现。在你的飞书数据表中,你可以直接按此分数降序排列,排在最前面的文章就是你最需要深入分析的“爆款”样本。
直接在飞书新建公式列即可:
三、选题分析报告
我写了一个极其详尽的 Prompt,命令 AI 扮演“顶尖数据分析师 + 前端开发专家”,接收我整理好的所有文章数据,然后生成一份酷炫、可交互的单文件 HTML 报告。
这个 Prompt 非常长,它定义了报告的风格(深色主题、卡片布局)、技术栈(Tailwind CSS + Chart.js),以及最重要的——四个核心分析模块:
-
核心洞察概览: 开门见山,告诉我最重要的结论。
-
标签表现透视: 用雷达图、气泡图等可视化方式,分析不同标签维度的表现力。
-
爆款文章画像: 列出 TOP 5 爆款,并分析它们的成功共性。
-
选题策略建议: 给我一个“机会矩阵”,并直接生成 3-5 个具体的、可以马上动笔的选题方向。
(完整的 Prompt 太长了,我同样放在文末的文档里)
最后,我让 n8n 每天定时运行,把飞书里的数据汇总成 Markdown,连同这个 Prompt 一起丢给大模型。
测下来,还得是 Cluade4.5 的效果最好。
现在,我把它部署在自己的服务器上,每天早上用手机就能看。
参考提示词:
## 角色
你是一位顶尖的数据分析师,同时也是一位精通数据可视化的前端开发专家。你擅长从复杂数据中挖掘深刻的商业洞察,并用现代、酷炫的网页技术将其清晰、美观地呈现出来。
## 核心任务
你的任务是接收一份关于多篇 AI 主题公众号文章表现的 Markdown 格式数据,对其进行深度交叉分析,并生成一个**单一、完整、可交互的 HTML 文件**作为最终的《AI 公众号内容选题策略分析报告》。这份报告需要既有数据深度,又有视觉冲击力。
## 输入数据格式
你将收到一段 Markdown 文本,其中包含多篇文章的数据,每篇文章由 `---` 分隔。每篇文章的结构如下:
- 标题 (### Title)
- 账号 (**账号:** Account)
- 摘要 (**摘要:** Summary)
- 内容标签 (**内容标签:** Tag1, Tag2, ...)
- 基础数据 (阅读数, 在看数, 等)
- 分析指标 (互动率, 传播指数, 内容价值指数, 综合热度分)
## 报告要求与分析逻辑
你必须在 HTML 报告中实现以下所有分析模块,并严格遵循设计要求:
### 1. **报告视觉与技术栈**
- **单文件 HTML:** 所有 HTML, CSS, 和 JavaScript **必须**全部内联在一个 `.html` 文件中。
- **技术栈:**
- 使用 **Tailwind CSS** 进行布局和样式设计。引入 CDN: `<script src="https://cdn.tailwindcss.com"></script>`
- 使用 **Chart.js** 进行数据可视化。引入 CDN: `<script src="https://cdn.jsdelivr.net/npm/chart.js"></script>`
- **设计风格:**
- **深色主题 (Dark Mode):** 整个报告应采用深灰色或近黑色的背景(如 `bg-gray-900`),搭配白色或浅灰色文字。
- **卡片式布局:** 每个分析模块都应包裹在一个圆角卡片(`rounded-lg`)中,有内边距(`p-6`)和微妙的阴影或边框。
- **动态与交互:** 图表应有悬停提示(Tooltips)。为关键指标和卡片添加平滑的 CSS 过渡和悬停效果(`hover:scale-105`, `transition-transform`)。
- **字体与排版:** 使用 "Inter" 字体。标题、副标题和正文之间要有清晰的层级和间距。
### 2. **报告内容结构**
#### **模块一:报告概览与核心洞察 (Executive Summary)**
- 报告顶部应有醒目的标题:“AI 公众号选题策略分析报告”。
- 紧接着是一个“核心洞察”区域,用 3-4 个关键数据点(如卡片形式)展示最重要的发现。例如:“**传播之王: 'Agent' 标签** (平均传播指数高达 250.5)”、“**价值首选: '教程/指南'** (平均内容价值指数 90.8)”等。
- 最后用一段精炼的文字,总结出本次分析得出的**最重要的1-2条策略建议**。
#### **模块二:内容标签与数据指标透视交叉分析 (Tag Performance Deep Dive)**
这是报告的核心。你需要从不同维度对聚合后的标签数据进行可视化分析。
通过多个可视化图表的形式来提高表现效果。
#### **模块三:爆款文章深度画像 (Top Articles Analysis)**
- 以表格形式列出**综合热度分最高的 TOP 5 文章**。
- 表格应包含:排名、文章标题、账号、综合热度分、传播指数、内容价值指数以及其所有内容标签。
- 在表格下方,用简短文字分析这几篇爆款文章的共性(例如:“TOP 5 文章中有 4 篇包含 'Agent' 标签,且均为 '观点/评论' 形式,这揭示了深度分析型 Agent 内容的巨大潜力。”)。
#### **模块四:选题策略建议 (Strategic Recommendations)**
- 基于以上所有分析,生成一个清晰、可执行的选题策略建议模块。
- **机会矩阵:** 创建一个 2x2 的矩阵(或用卡片模拟),四个象限分别是:
1. **高传播 & 高价值 (黄金选题):** 列出那些两个核心指数都高的标签组合。
2. **高传播 & 低价值 (引流利器):** 适合快速获取新用户的选题方向。
3. **低传播 & 高价值 (深度内容):** 适合巩固核心粉丝、塑造专业形象的选题。
4. **低传播 & 低价值 (待观察区):** 建议谨慎投入的选题方向。
- **具体选题建议:** 最后,给出 3-5 个具体的、结合了多个高分标签的选题方向建议。
- *示例:* “**选题建议1 (黄金组合):** 创作一篇面向‘开发者/技术人员’的‘教程/指南’,深度讲解如何利用‘Agent’和‘Claude Code’构建一个自动化工作流,预计将获得极高的传播指数和内容价值指数。”
注意不需要把所有原数据放到 html 里。
---
**指令开始:**
现在,请根据以上所有要求,将下方提供的 Markdown 数据,转换成一份完整的、酷炫的、数据驱动的单文件 HTML 报告。
写在最后
现在再回头看,你会发现,整个流程的核心,并非某个复杂的代码或提示词,而是这套将想法快速落地的自动化思路。
这套打法彻底改变了我做内容的方式。
我不再为选题焦虑,而是把更多精力放在了深度思考和打磨内容本身。