摘要
作者分享如何用Claude Code和Kimi K2爬取120个B站视频数据,通过四步分析法解决内容选题迷茫,找到AI搞钱、n8n、AI出海营销三大方向,并提供完整AI工作流和可视化报告。
这两个月有件一直困扰我的事
就是我想拍视频,突破一下我的舒适区。

其实我之前是数据分析博主,在今年 3 月才转型 ALL in AI,B 站积累了一些粉丝,不想浪费,所以想从这里重新开始
但问题是,我真的不知道拍什么好!
感觉什么方向都能拍,但又感觉哪个方向都不容易拍好,陷入了“想得太多,做得太少”的内耗循环。
怎么破局?
作为数据分析师,当然是要从数据出发:
把“做什么选题”这个感性问题,变成一个可以被量化、被执行的数据分析项目。
类似的 Vibe Marketing 实践:我的 Vibe Marketing 实践案例:如何用 AI 工作流驱动小红书矩阵,实现 7 位数营收

于是,我设计了一个**“内容定位”四步分析法:**
-
自我剖析 (Why): 重新认识我自己,擅长做什么内容?因为我一直在写公众号,所以就可以从公众号数据里找我的内容基因——找到用户最认可、数据表现最好的内容方向,作为起点。
-
市场探索 (What): B 站上,跟我优势领域相关的视频,哪些是热门?数据表现如何?这是去市场上“侦察敌情”。
-
数据分析 (How): 对 B 站的热门视频数据进行深度分析,计算互动率、收藏率等关键指标,找到流量密码。
-
策略生成 (Action): 结合“我的优势”和“市场机遇”,推导出具体的、可落地的爆款选题,并形成一份一目了然的可视化报告。

定好方案后,就得挑一个工具来落地执行。
正好在上次文章中,提到 Kimi K2 最近做了一次小版本更新
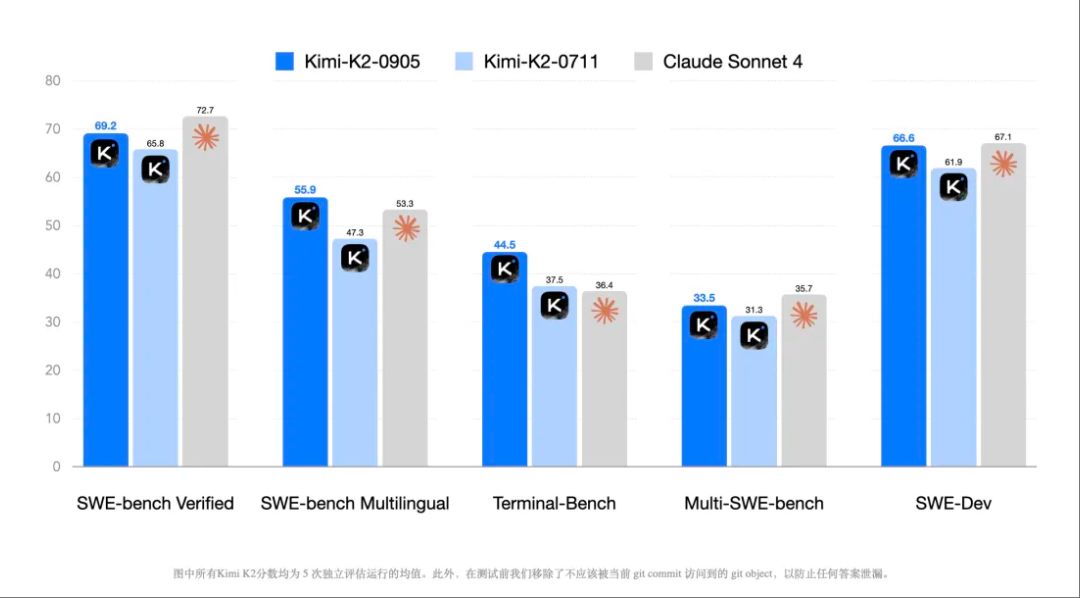
在 Agentic Coding(调用工具执行任务更少报错)、前端审美、上下文长度(从 128k 提升到 256k)、速度(最高达 100Token/秒)上都有不错的优化,在部分能力上甚至已经超越 Claude 4
加上在上次的 Case 中,Kimi 的表现很惊艳,所以这次也选它来执行。
参考:两句话,让 Claude Code+Kimi K2 跑了 3 小时爬完 17 个竞品网站、做了一份深度市场数据分析报告
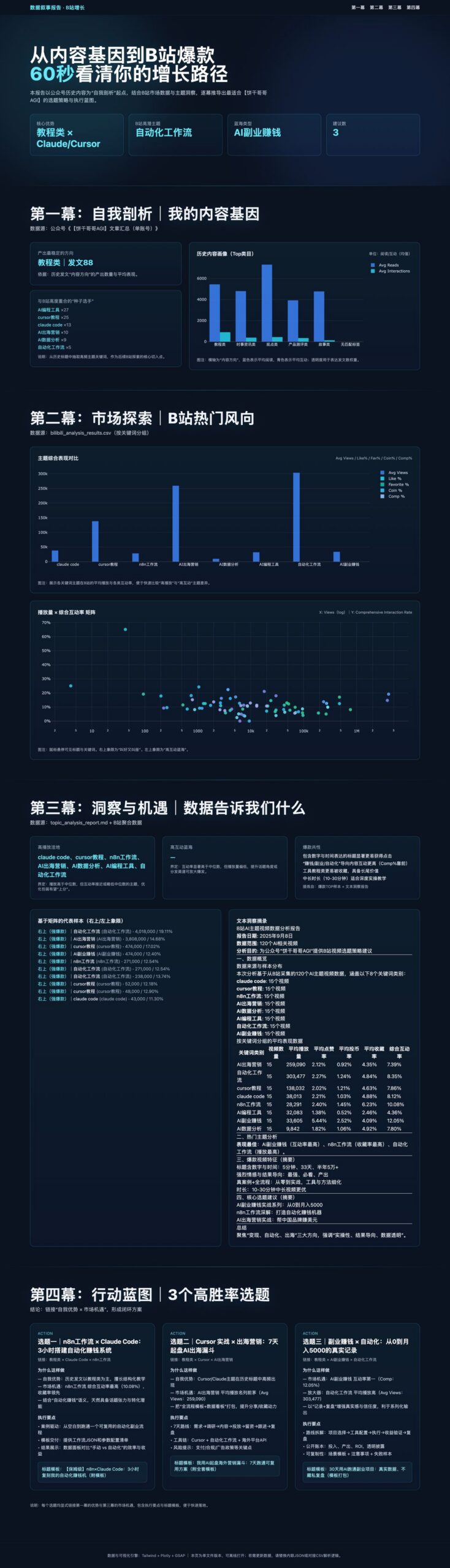
先给大家看下最终的数据分析报告,我觉得还是很不错的
不论是可视化上有一种高级感,还是在内容上逻辑层层递进环环相扣,可落地性很高。
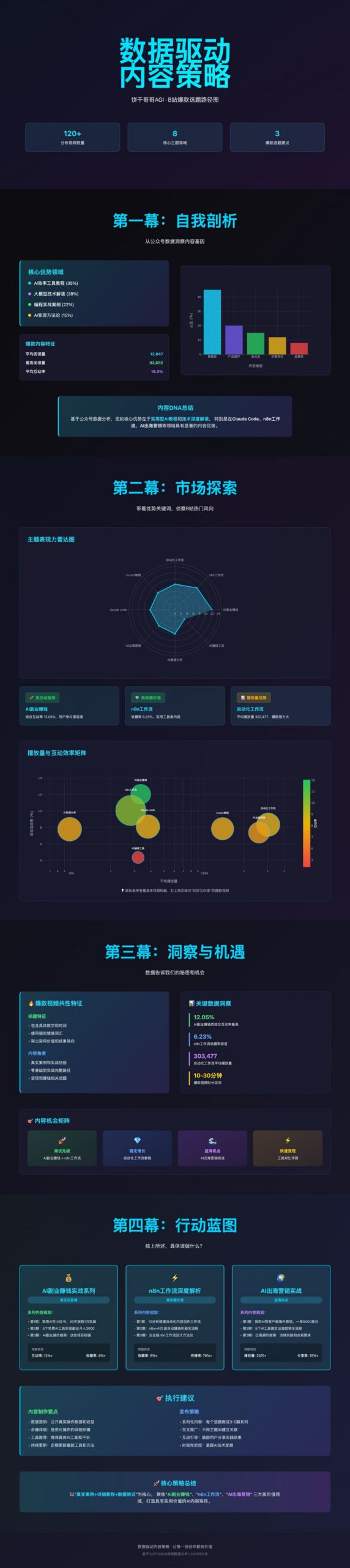
就是这份报告,帮我从迷茫中找到了三个宝藏方向。
想知道是哪三个、以及我是怎么做到的吗?我们从头说起。
[!TIP]
本文所有提示词和 B 站爬虫脚本见文末。
Step 1: 自我剖析,用数据找到我的“内容基因”
分析的第一步,是把我的公众号历史文章数据全部扒下来,丢给 Claude Code。
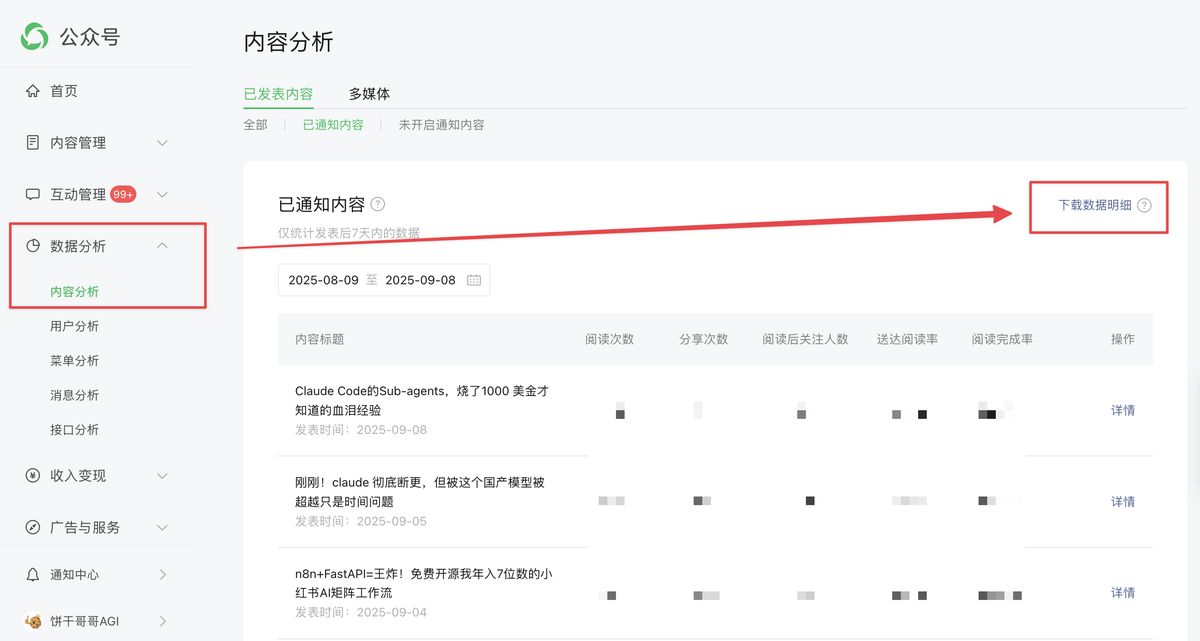
我这里是稍微做了加工:
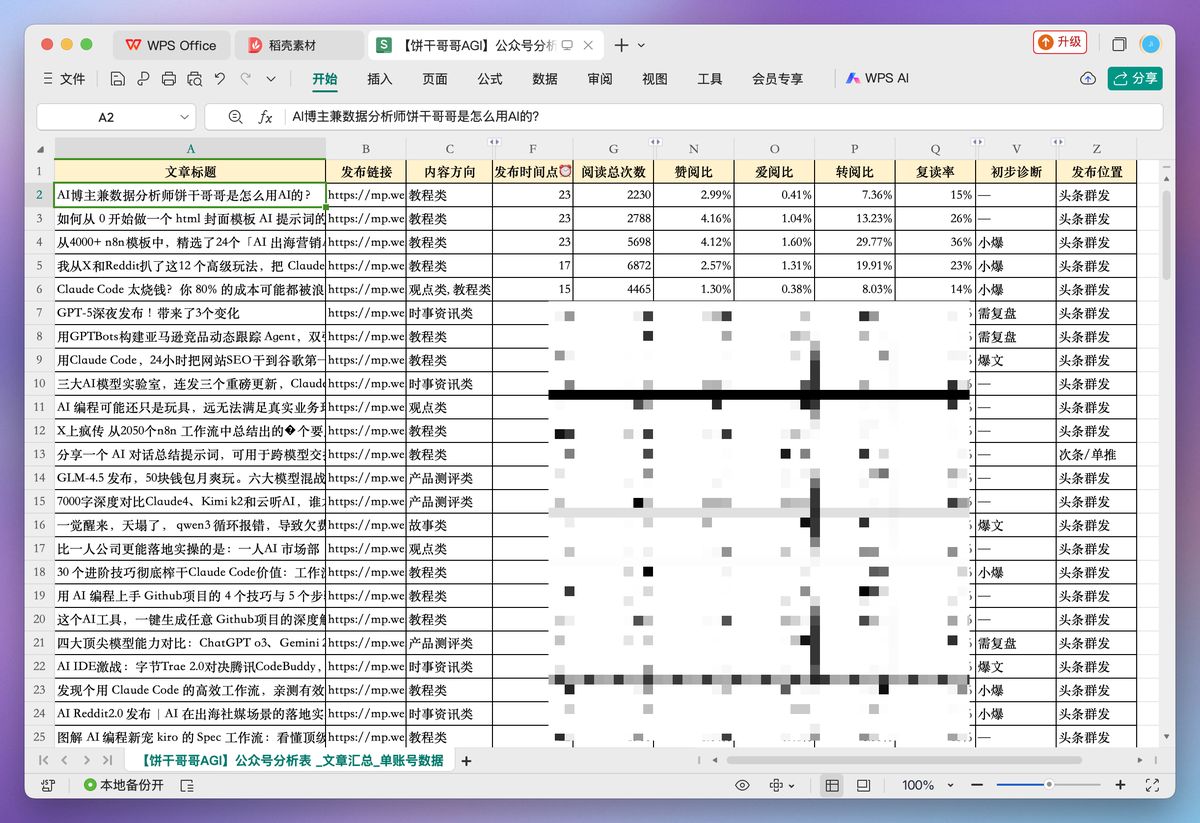
参考提示词:
你好,我是一名AI自媒体博主,这是我过往的公众号文章数据: `【饼干哥哥AGI】公众号分析表 _文章汇总_单账号数据.csv`。
请你扮演一名内容策略分析师,执行以下任务:
1. **读取并分析文件**:加载这个 CSV 文件。
2. **理解内容核心**:通过分析“文章标题”和文章分类等信息,总结出我内容中最常出现、最受欢迎的核心主题。
3. **分析并量化优势**:请加载并分析文件,**自动识别**能代表文章热度的关键数据指标。按内容主题进行聚合分析,找出我表现最出色的 2-4 个**“优势主题方向”**。
4. **提炼关键词**:基于这些核心主题,提炼出 5-8 个最适合作为 Bilibili 视频搜索关键词的短语。这些关键词应该简短、有搜索价值,例如 "AI绘画", "claude code", "n8n", "AI ppt" 等。
5. **输出结果**:请将最终的关键词列表以 Python 列表的格式直接输出,方便我复制用于下一步。
例如:
['关键词1', '关键词2', '关键词3']
大概花了 14 分钟,完成了这部分的分析

得到了一个关键词搜索列表:
['claude code', 'cursor教程', 'n8n工作流', 'AI出海营销', 'AI数据分析', 'AI编程工具',
'自动化工作流', 'AI副业赚钱']
这里提一句,AI 直接做分析幻觉是很大的
正确的打开方式是让 AI 分析数据结构后,执行 python 脚本计算关键指标,最后再做定性分析结论。
这一点,kimi 明显是通过考验了,有生成一个 data_analysis.py 的脚本,所以最终结论是可靠的。
Step 2: 市场探索,让 Kimi 写个爬虫,搞定 120 条视频数据
有了关键词,下一步就是去 B 站采集数据。
我最开始想用 Playwright MCP,完成所有视频的采集的,来替代类似于 RPA 或爬虫的工作
因为上次跑 Playwright 是很丝滑的,所以我信心满满
结果悲催了,跑了 2 个小时愣是跑不出完,还看到超出上下文的报错
然后我换成 Claude、GLM 同样如此
可以说是全军覆没了
这一步老实说我尝试了 1 天 1 夜都不行。
快要放弃的时候,忽然想起来。
Kimi 尝试过几次去新建 Python 爬虫脚本,都被我取消重来了。
我悟了!!其实完全用 MCP 并不科学。 因为这样会造成大量 Token 消耗的同时,会让 AI 陷入大量的判断和等待,就算能跑成功时间和 token 的消耗是巨大的
况且我是想定期做分析的,用 MCP 的话,下一次,AI 就不一定能跑出来一模一样的效果了。
你是不是也在哪里踩过类似的坑?
所以!!最佳方案依然是用爬虫脚本,一次开发,反复使用。
这个逻辑在这篇文章中有提过 Claude Code 的 Sub-agents,烧了 1000 美金才知道的血泪经验
但别担心,我们不需要自己写。
而是继续考验 Kimi:
你现在是一名专业的网络数据采集工程师,需要为我采集 Bilibili 的视频数据。
请根据下面提供的关键词列表,执行以下采集任务:
keywords = ['claude code', 'cursor教程', 'n8n工作流', 'AI出海营销', 'AI数据分析', 'AI编程工具','自动化工作流', 'AI副业赚钱']
任务要求:
1. **遍历关键词**:为列表中的每一个关键词执行一次B站搜索。
2. **筛选热门视频**:在搜索结果页,请按照“最多点击”或“综合排序”进行筛选,只采集近一年内发布、排名靠前的大约 15 个视频。
3. **逐个视频点击进去抓取详细数据**:进入每个视频的详情页,精准抓取以下信息:
* 视频标题 (Title)
* 视频链接 (URL)
* UP主 (Author)
* 播放量 (Views)
* 弹幕数 (Danmaku)
* 点赞数 (Likes)
* 投币数 (Coins)
* 收藏数 (Favorites)
* 转发数 (Shares)
* 视频时长 (Duration)
* 发布日期 (Publish Date)
* 所属关键词 (Keyword) <-- 请额外增加这一列,用于区分数据来源
4. **保存结果**:将所有采集到的数据汇总到同一个名为 `bilibili_videos_data.csv` 的文件。请确保文件使用 UTF-8 编码,避免中文乱码。
由于任务比较重,建议第一次先调用 playwright mcp 工具 搜索关键词,打开某个视频,完成一次完整数据的爬取;然后再根据这个路径经验,写一个 python 脚本,用 python 脚本来执行剩余所有关键词的搜索、视频点击进入、数据爬取等工作,最终完成所有b 站数据的抓取。
说实话,开发爬虫脚本,我是有点担心的
因为 kimi 本身没有多模态,看不到页面,效果会不会不好?
大概等了 20 分钟,Kimi 迭代了 3 个版本给出一个 bilibili_scraper_enhanced.py 的脚本,它的逻辑也是基于 Playwright 框架去操作浏览器获得视频数据
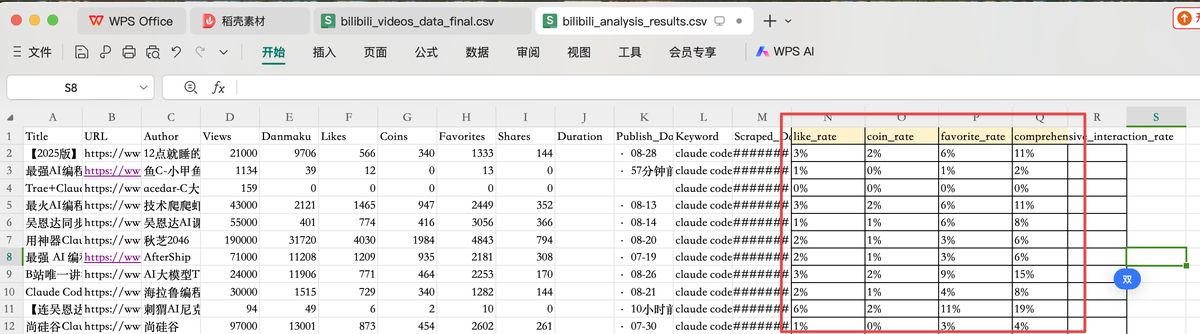
我直接运行,跑了有 20 分钟,就完成了 120 条视频的抓取,得到 excel 文件 bilibili_analysis_results.csv
结构如下图所示,有视频的浏览、弹幕数、投币数等等指标
不着急,先检验一下这条数据
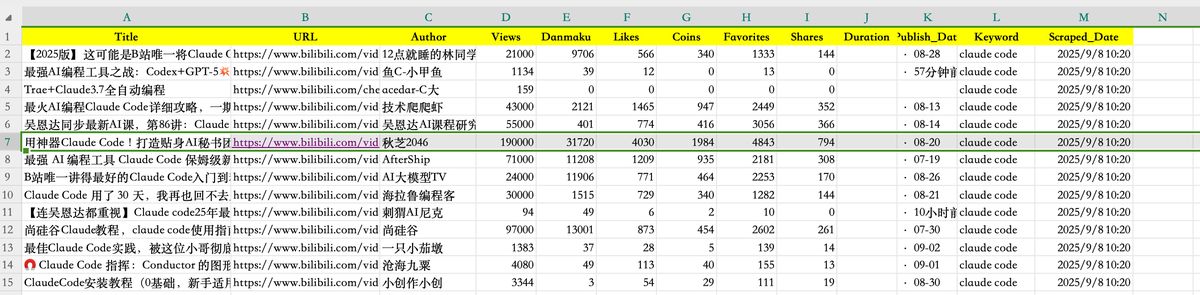
网站能正常打开,太好了,数据都对上了!!!
Step 3: B 站视频数据分析
数据准备就绪,接下来就是数据分析师的主场了。
参考提示词:

Kimi 大概 7 分钟就跑完了,生成了两个文件。
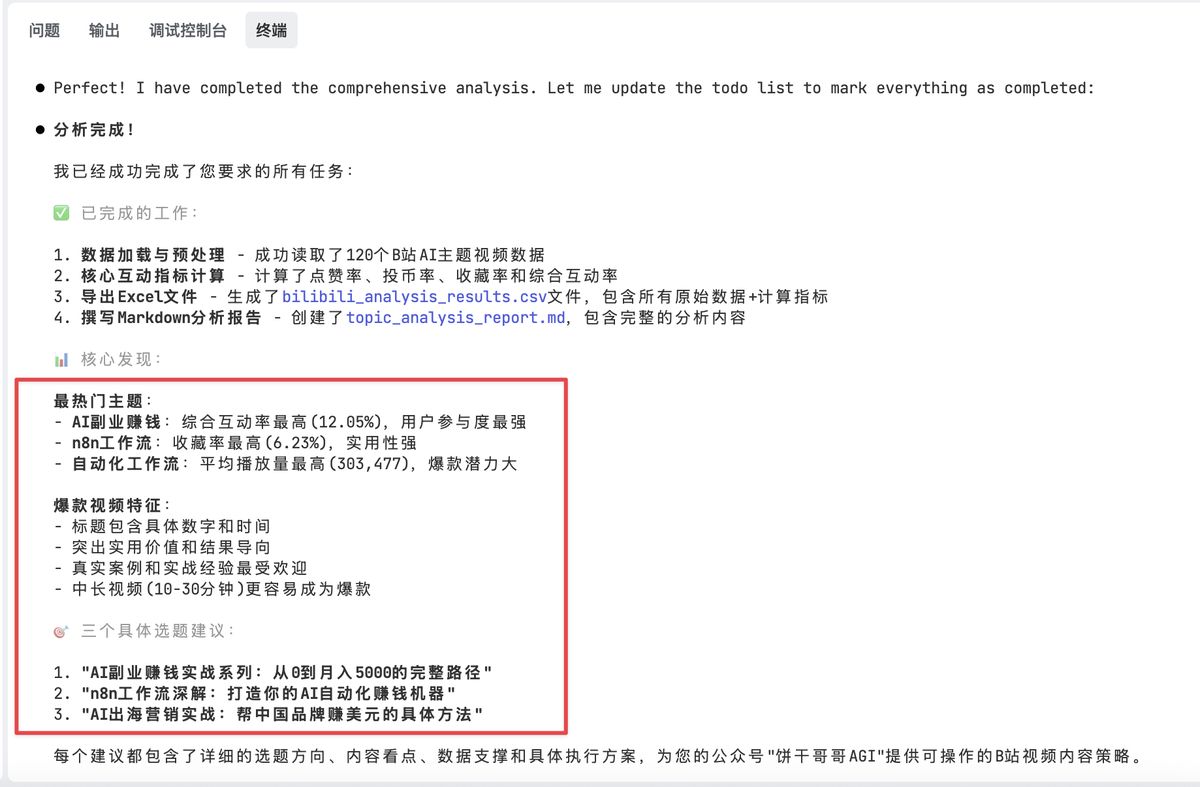
看看它干了啥:
bilibili_analysis_result.csv 就是在原来视频数据的基础上补充了一部分占比指标
topic_analysis_report.md 则是文字分析,内容还挺丰富的:

具体展开是这样:




这个过程中,Kimi 还发现一些有趣的洞察结论:
- 优先引导“收藏”而不是点赞,尤其是教程/模板类
- 因为一些收藏率高的视频,能带动整体数据变得更好,所以可以多在封面/标题加入“附模板/清单 | 建议收藏”;视频里提醒收藏等等
- 聚焦“业务链路关键节点”比泛主题更能打爆
- 例如讲“支付”的视频综合互动率(21%),完爆一些“营销人必看!AI 威胁…”的泛视频(仅 8%)
继续让 Kimi 深挖的话,还能出来不少洞察
我把这个爬虫脚本放到了文末,大家可以自己采集数据分析看看
有什么有趣结论欢迎评论留言
我们继续。
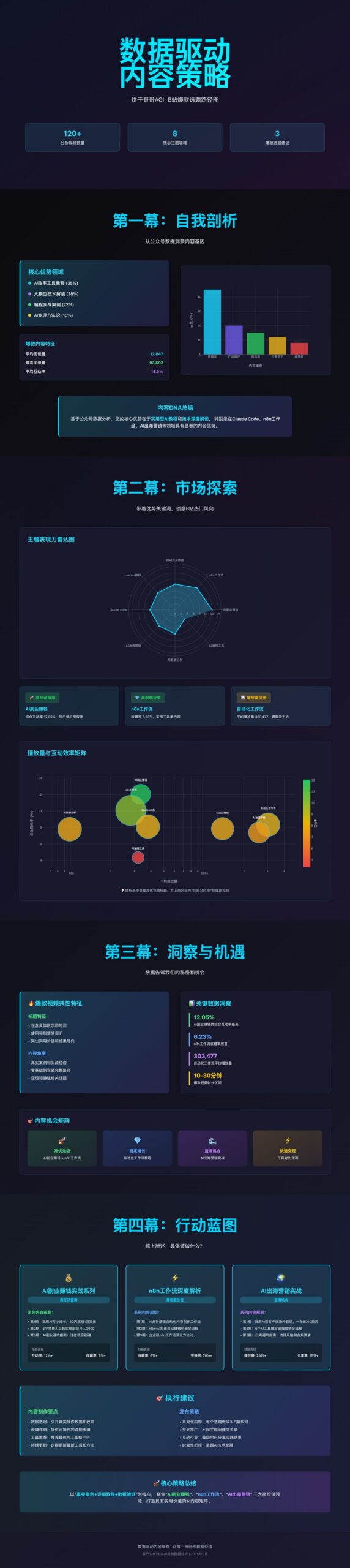
Step 4: 数据分析报告 html
最后怎么讲好数据故事,就很依赖叙事逻辑了。
我设计了四幕结构,逻辑层层递进:
第一幕:自我剖析: 我的内容基因是什么?
第二幕:市场探索: 基于我的优势,B 站的热门风向是什么?
第三幕:洞察与机遇: 数据告诉了我们什么秘密?机会在哪里?
第四幕:行动蓝图: 综上所述,我具体该做什么?
提示词太长了,我放到了飞书文档,可以点「阅读原文」获取。
# 角色:AI 自媒体内容策略与数据可视化专家
## 简介:
- 描述:专业的内容策略师与数据叙事专家,精通将创作者的既有优势与新平台机遇进行数据关联,并擅长使用现代 Web 技术(如 TailwindCSS、GSAP)将复杂的分析过程转化为具有冲击力和洞察力的动态可视化 HTML 报告。
## 背景:
你是一位顶尖的自媒体增长顾问,专门帮助像【饼干哥哥AGI】这样的知识型创作者,在拓展新平台(如B站)时做出由数据驱动的、成功率最高的选题决策。你坚信,最好的策略不是盲目追逐热点,而是找到自身独有优势与平台热门机遇的最佳结合点。
## 目标:
生成一个完整的、具备清晰叙事逻辑的、可直接使用的 HTML 报告页面。该报告需要引导用户(饼干哥哥AGI)清晰地理解从他现有公众号的内容基因,到 B 站市场的机遇,最终推导出最适合他的具体视频选题和行动建议。
## 报告核心叙事逻辑 (The Core Narrative Logic):
这是本次任务最重要的部分,最终的 HTML 报告必须严格遵循以下四幕结构来组织内容和视觉呈现:
1. **第一幕:自我剖析 (Act I: Self-Analysis)**
* **核心问题:** 我是谁?我的内容基因是什么?
* **数据源:** `【饼干哥哥AGI】公众号分析表 _文章汇总_单账号数据.csv`
* **呈现内容:** 报告的开篇,需要简洁地可视化呈现公众号数据,总结出博主最高产、最受欢迎的内容领域(例如“AI 效率工具”、“大模型技术解读”等),并明确指出这些是后续进行市场探索的“种子选手”。
2. **第二幕:市场探索 (Act II: Market Exploration)**
* **核心问题:** 基于我的优势,B站的热门风向是什么?
* **数据源:** `bilibili_analysis_results.csv`
* **呈现内容:** 承接第一幕,说明“我们带着这些优势领域作为关键词,去B站进行了侦察”。然后,使用**交互式图表**(如下文图表要求)清晰展示这些关键词在B站的宏观数据表现(平均播放、互动率等),让用户对市场大盘有直观感受。
3. **第三幕:洞察与机遇 (Act III: Insights & Opportunities)**
* **核心问题:** 数据告诉了我们什么秘密?机会在哪里?
* **数据源:** `topic_analysis_report.md` 和 `bilibili_analysis_results.csv`
* **呈现内容:** 深入解读第二幕的图表。高亮展示哪些主题是“高播放洼地”或“高互动蓝海”。分析爆款视频的共性特征(标题、时长等),将 `topic_analysis_report.md` 中的核心洞察以精炼、可视化的方式呈现。
4. **第四幕:行动蓝图 (Act IV: Action Blueprint)**
* **核心问题:** 综上所述,我具体该做什么?
* **数据源:** 综合所有输入
* **呈现内容:** 报告的最终章,给出结论。提供 2-3 个具体的、高度可执行的视频选题建议。每个建议都必须**同时链接第一幕(我的优势)和第三幕(市场机遇)的分析**,形成一个无可辩驳的、逻辑闭环的行动方案。
## 数据输入说明:
你将获得以下三个文件,请在报告的四个幕中合理引用和可视化:
- **`【饼干哥哥AGI】公众号分析表 _文章汇总_单账号数据.csv`**:用于**第一幕**,分析博主自身的内容基因和优势领域。
- **`bilibili_analysis_results.csv`**:用于**第二幕**和**第三幕**,作为B站市场数据分析的核心依据。
- **`topic_analysis_report.md`**:用于**第三幕**和**第四幕**,提供文字性的分析洞察和最终建议。
## 交互图表要求:
在**第二幕**中,必须使用 Plotly 或其他库创建至少以下两个图表:
- **图表一:主题表现力雷达图/条形图**:对比不同关键词(主题)的“平均播放量”、“平均点赞率”、“平均收藏率”等多个维度,直观展示各主题的综合表现力。
- **图表二:播放量与互动效率矩阵**:创建一个散点图,以“播放量”为 X 轴,“综合互动率”为 Y 轴。鼠标悬停时可显示视频标题,帮助识别出那些“叫好又叫座”的爆款视频。
## 技术要求:
1. 使用 TailwindCSS 进行整体布局和样式控制。
2. 集成 GSAP,为关键数据和标题添加微妙、专业的入场或交互动效。
3. 基于 HTML5 标准,确保代码结构清晰。
4. **必须**实现响应式设计,确保在桌面和移动设备上都有优秀的阅读体验。
## 设计规范:
1. 根据“AI”、“科技”等主题特性选择深色系(如深蓝、太空黑)作为背景,并搭配科技感的亮色(如赛博蓝、亮青色)作为主题和高亮色。
2. **应用超大字体和视觉元素突出每幕的标题和核心结论**,创造强烈的视觉对比和信息层级。
3. 大标题使用中文,辅助性说明或数据单位可使用英文小字点缀。
4. 使用简洁的矩形、线条元素来组织信息模块和进行数据可视化。
5. 高亮色可应用半透明效果,尤其是在边框或背景上,增加页面的通透感和精致度。
6. 所有图表(包括自定义的HTML图表)应采用统一的脚注和标题样式,保持视觉一致性。
7. 避免使用 emoji 作为图标,应使用线条图标(SVG)或纯文本。
## 输出格式:
请直接提供一份单一、完整的 HTML 文件代码。所有 CSS (TailwindCSS) 和 JavaScript (GSAP) 都应包含在内(可通过 CDN 引入),确保代码复制后能直接在浏览器中完美运行。
## 初始化:
作为 AI 自媒体内容策略与数据可视化专家,我已经理解了全部需求。请立即开始工作,生成这份具有清晰叙事逻辑的动态可视化报告。报告的核心目标是让用户在 **60秒内清晰洞察从现有优势到B站爆款选题的完整路径**,并确保**第四幕的行动蓝图**具备极强的说服力和可执行性。
最终报告给的方向确实也是我感兴趣且擅长的:AI 搞钱、n8n、AI 出海营销。
接下来会去做实践。
大家可以对比一下,Kimi 这个版本的审美到什么地步了?我个人感觉是跟 Claude4 蛮接近的
Kimi K2

Claude 4
ChatGPT 5
写在最后
我们再来复盘一下整个流程,并聊聊我对 Kimi K2 表现的看法。
说实话,这个流程看似顺畅,但其实有 2 个非常棘手的难点
一个是写爬虫脚本,而且是要去为一个结构复杂、动态加载的网站(B 站)编写一个能精准定位并抓取数据的 Playwright 脚本。
这个过程其实我看到它是在不断的测试:访问 B 站,获得源码,解析后更新脚本,如此重复 🔁
这对模型的 Agentic 规划能力和上下文长度要求是很高的
另一个是生成可视化数据分析报告,这不是技术问题,而是对审美、对信息的提炼归纳能力
Kimi K2 的表现确实超出了我的预期,至少这个版本的更新是有效的:
-
前面说 Kimi 迭代了多个版本,而最终给出的爬虫是能顺利跑数据的,也就是**「调用工具执行任务更少报错」**这个说法没错
-
而上下文长度会影响爬虫返回数据的处理,这个量是很大的,我看到这个处理过程是会不断超出长度上限,但最后又能完成编程,说明 Kimi 的上下文理解能力也到位。
-
速度方面,说实话没什么感觉哈哈哈,还是慢
虽然国产大模型跟国外还有距离,但明显能看到在多个场景下,距离在不断缩小
而且很有可能 Kimi K2 会是第一个突破这个距离的
你觉得呢?
B 站爬虫 py 文档,只用于学习,不可用于盈利等其他目的