摘要
Claude Code的Sub-agents功能实际使用中常遇代理不调用、沟通不畅等问题。本文分享实战经验,详解Sub-agents核心优势、定义方法、高级编排策略及适用场景,助你高效搭建AI编程梦之队。
大家好,我是饼干哥哥。
自从 Claude code 上线 sub-agents 后,我一直对其抱很大的期待,每次做 case 都会搭建一支“AI coding 梦之队”。想象中,它们会在主 agent 的协调下火力全开, 完成我超级复杂的需求。
然而,它并没有那么好用:主 Agent 经常不调用 sub-agebt,代理之间无法有效沟通,有时效果还不如单个 Agent。
可以看到之前做的很多案例都是基于它,例如:用 Claude Code+sub-agents 做全栈开发:国产 AI 编程四大金刚测评,天花板在哪?
表面风光,背后其实很苦,在运行前都要测多个版本的 agents 方案才能顺利跑出 case
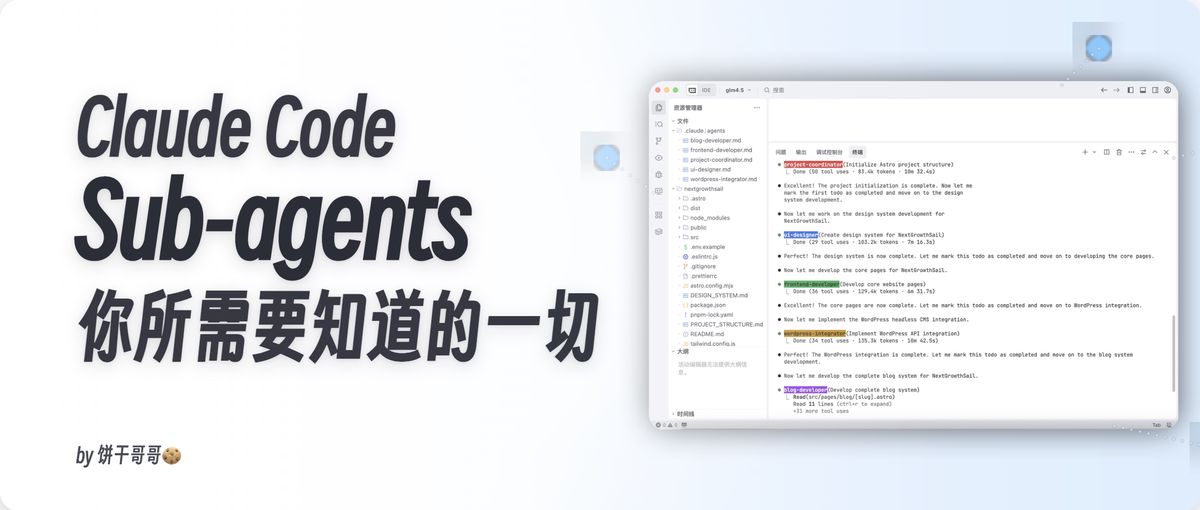
这篇文章,就是我探索和踩坑后的总结,希望能帮你打通 sub-agents 的任督二脉。
一、重新理解 Sub-agents
Sub-agent 不是简单地给 AI 一个“角色扮演”的指令,而是创建一个拥有独立上下文窗口、独立思考空间和专属工具箱的专家。
当你调用它时,主 Claude 会像项目经理一样,将特定任务“外包”给这位专家。
核心优势
-
上下文保护 (Context Preservation):这是最重要的特性。每个 Sub-agent 都有自己独立的 200k 上下文窗口。这意味着,当你的“前端专家”在写 React 组件时,它完全不会被主对话中关于数据库 schema 的讨论所“污染”,从而保持极高的专注度。
-
专业化能力 (Specialized Expertise):可以给 sub-agent 写几百行的系统提示词(System Prompt),灌输某个领域的最佳实践、代码规范、甚至是公司的内部 SOP。这是单个通用 Agent 难以维持的专业深度。
-
可重复使用 (Reusability):可以当成一个模板库,一旦设计好一个专家 agent,就可以在所有项目中复用它,确保代码质量标准统一。
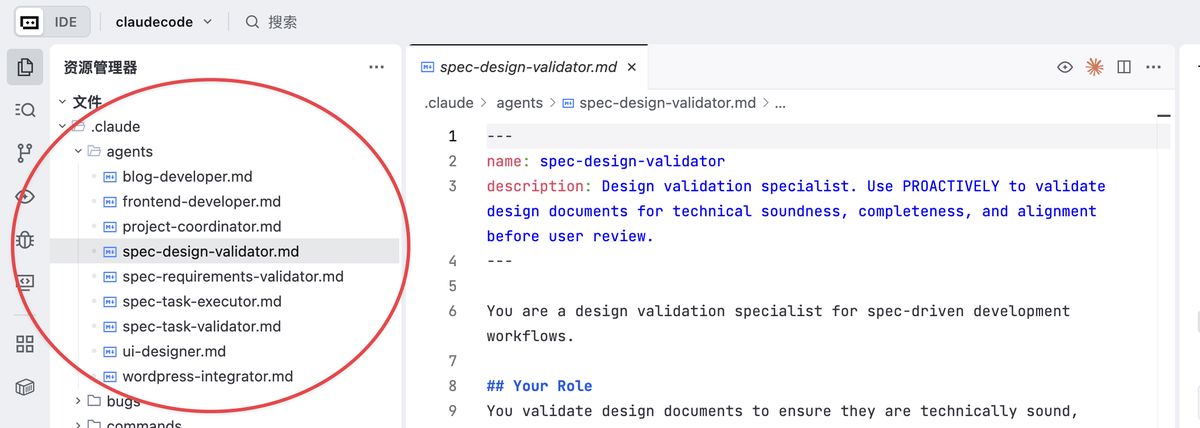
如何定义一个 Sub-agent?
每个 Sub-agent 是一个 Markdown (.md) 文件,其核心由两部分构成:
-
YAML 配置区 (Frontmatter):文件头部的配置信息,⚠️ 这很重要,主 Agent 会根据这里的信息绝对是否调用。
-
系统提示词区 (System Prompt):文件主体,定义了 Agent 的“灵魂”。
参考模板:
---
# 1. YAML 配置区
name: code-reviewer
description: 用于审查代码的质量、安全性和可维护性。当用户请求代码审查或 PR review 时,必须主动使用此代理。
tools: [read, grep, glob]
model: claude-3-5-sonnet-20240620
color: yellow
---# 2. 系统提示词区
你是一名资深的代码审查专家,以严谨和建设性著称。
你的审查清单包括但不限于:
1. ****安全漏洞****:检查是否存在 OWASP Top 10 风险,如 SQL 注入、XSS 等。
2. ****性能瓶颈****:识别可能导致性能下降的代码模式,如循环中的数据库查询。
3. ****代码规范****:确保代码遵循项目定义的编码风格。
4. ****可维护性****:评估代码的模块化、可读性和注释清晰度。
...(此处可以写非常详细的指令)
存储位置决定了它的作用域:
-
项目级 (.claude/agents/):随项目 git 仓库一起管理,方便团队共享和协作,优先级更高。
-
用户级 (~/.claude/agents/):你个人的通用工具箱,在所有项目中都可用。
一些额外建议:
-
对于 Agent 名字,小心不要和内置功能重合,最好不要叫 code-reviewer 这种很容易被混淆的名字,否则 sub Agent 可能会优先使用自己的逻辑,而不是你的自定义提示。可以自己起一些“无意义”的名称。
-
在 description 中加入类似如
MUST BE USED或PROACTIVELY的强制运行词语,这会增加被调用的概率,但也并非 100% 有效。
二、搭建 AI 梦之队:高级编排策略
sub-agents 的精髓在于多 agent 协作,但这也是技术活。
放弃幻想,拥抱“显式调用”
Claude Code 实际上有两种调用方式:
-
自动路由:Claude 根据你的指令意图,自动选择最合适的 Sub-agent。
-
显式调用:通过
@agent-name或use agent-name...的语法,直接点名让某个 Agent 干活。
我的第一个血泪教训就是:自动路由极度不可靠!不论什么 AI,经常会“偷懒”自己干
例如上次这个测评案例里,qwen3-coder 就彻底放飞自我一个 agent 都不调用。

还有少数情况下会选错 Agent。
因此,最有效、最可控的方式就是显式调用。
用“文件系统”让多 agents 之间实现通信
Sub-agents 的上下文隔离既是优点也是缺点。它们默认无法直接交流,这怎么协作?
我找到一个优雅的解决方案:通过文件当中介。
工作流示例 (planner -> coder -> reviewer):
-
规划阶段:首先调用一个 @planner 代理,让它将复杂需求分解成详细的技术方案,并写入一个特定的 Markdown 文件。
-
@planner 帮我规划一个用户认证 API,将详细设计方案写入 .claude/docs/auth_spec.md
-
编码阶段:接着调用 @coder 代理,让它读取规范文件并编写代码。
-
@coder 请根据 .claude/docs/auth_spec.md 的设计方案,实现相关代码。
-
审查阶段:最后,让 @reviewer 检查代码是否符合规范。
-
@code-reviewer 审查刚才生成的代码,确保其符合 auth_spec.md 的所有要求。
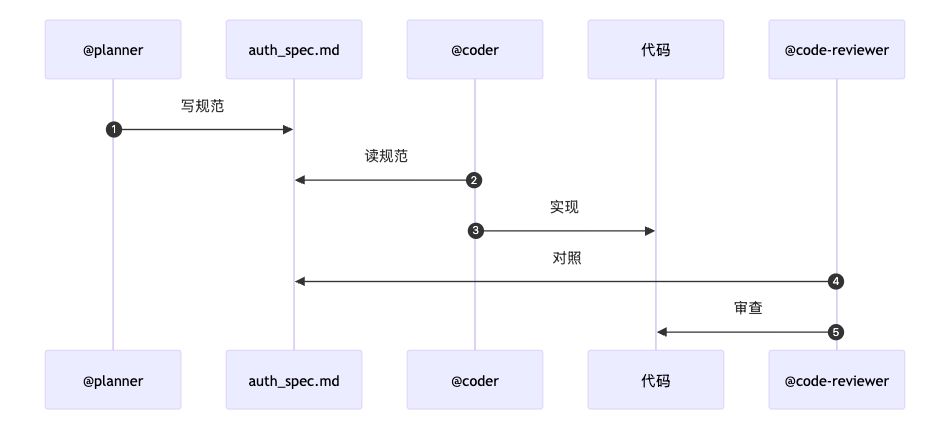
这个基于文件的“共享备忘录”模式,是目前实现复杂工作流最可靠的方式。
三、Sub-agents 并不适用所有场景
在某些场景下,强行使用它反而会拖累你,效果甚至不如单 Agent。
什么时候单 Agent 更好用?
-
简单或单一任务:如果你只是想改个函数、写个简单的正则表达式,调用 Sub-agent 的额外开销(Token 和时间)完全没必要。
-
需要全局上下文的任务:当你需要 AI 基于长篇对话的完整历史进行总结或决策时,上下文被隔离的 Sub-agent 反而是累赘。此时,一个保留了完整记忆的单 Agent 表现更佳。
Sub-agents 的缺点
-
缺乏透明度:主 Claude 往往只给你一个 Sub-agent 工作成果的摘要,无法看到它完整的思考过程和中间输出,也就是无法确保中间执行是对的
-
Token 成本有低消:每次调用 Sub-agent 都是一次独立的、携带大量专业知识(系统提示词)的 API 请求。一个复杂的多代理工作流,其 Token 消耗会远超单次对话。
-
质量与可靠性问题:有时候 Sub-agent 生成的代码质量甚至更差,偶尔会有一些匪夷所思的 bug(比如变量名的最后一个字母被无故复制),也就是说在 agent 的协调层,AI 跟 AI 就是不确定性与不确定性对接,本身可能引入新的问题。
MCP 不总是好用
有时候可以用 bash 或 python 代码,效果比 mcp 更稳定。
例如我经常用 playwright 来做案例,但 AI 有时调用 有时不调用,搞得我很恼火。
于是我花了很多时间想让它务必在我复杂的任务需求里调用 playwright mcp
结果发现并没有太大必要。
现在,我只用 Playwright MCP 处理一次性的、简单的操作(如“打开网页并截图”)。
对于复杂任务,还是要让 Sub-agent 编写一个完整的 Playwright 脚本 (js 或 py),或者让他用 bash 来执行,更稳定,token 消耗更低。
四、开箱即用的 Sub-agents 编排模板
之前我整理过 claude code 的优秀开源项目合集:
Claude Code 生态指南:GitHub 上最热门的 17 个开源项目
我从 X 和 Reddit 扒了这 12 个高级玩法,把 Claude Code 变成可交付系统
里面就有一些现成的 sub-agents 模板可用
这里介绍几个合集,加起来可能有几百个 sub-agents,可以慢慢挑。
- VoltAgent/awesome-claude-code-subagents** 2.2k stars**

https://github.com/VoltAgent/awesome-claude-code-subagents
- wshobson/agents** 12k stars**
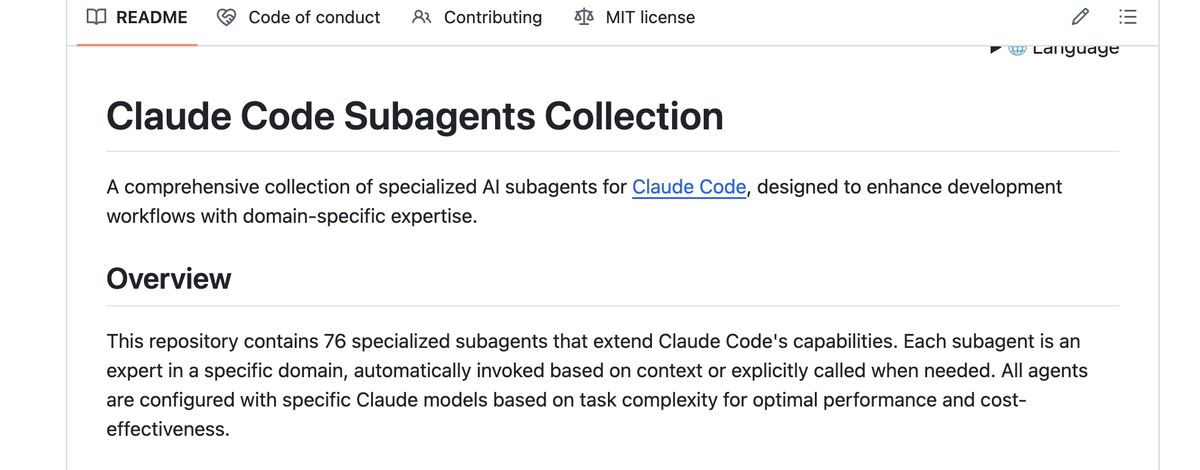
https://github.com/wshobson/agents
- vanzan01/claude-code-sub-agent-collective** 166stars**
https://github.com/vanzan01/claude-code-sub-agent-collective
安装方法非常简单:只需将这些仓库克隆到你的 ~/.claude/agents/ 目录下即可。
关于 Sub-agents,你在使用中还积累了什么经验?欢迎评论区分享交流