摘要
厌倦了华而不实的AI界面?本文实测GLM-4.5等六大模型,聚焦一键生成真正可用的应用。发现GLM-4.5以初级应用架构师思维,实现功能闭环,成为最务实的AI工程师。
思路大纲
方向:拒绝 UI 花架子!GLM-4.5 vs Gemini vs Kimi,AI 一键生成“真·可用”的应用,谁在裸泳?
⚠️ 重点要求:这个模型实力基本是初级应用架构师,AI 成为了自己的工程师 这个点可以多强调、带一下心智。就打这个定位:初级应用架构师。
想法:现在很多大模型都关注前端网站的美化,因为这是最直观能让人看到的。但其实真正重要的是应用能跑起来,也就是藏在前端背后的后端功能得能实现。而这是我认为 z.ai 这次大模型更新的重点:
例如做一个谷歌搜索网站,以往做的测试都只是个样子,但 z.ai 出来的效果很惊人:是真的能搜索的。
目录:
- 开头
-
引子: 简述智谱清言 GLM-4.5 的发布,提及其专为智能体(Agentic)应用打造的定位。
-
点明主线: 抛出核心观点——当前大模型评测普遍侧重 UI 美观度,却忽略了应用能否“跑起来”的本质。一个能实现真实功能的应用,远比一个静态网页更能体现 AI 的智能。
- 切入到前面说的,真正可用的网站,如谷歌搜索网站,为什么?对应背后的特性是什么?
反面案例(花架子): 以往模型生成的“谷歌搜索”,只是一个带输入框和按钮的 HTML 静态页面,点击后毫无反应。
正面案例(真·可用): GLM-4.5 生成的“谷歌搜索”,是一个自包含的 HTML 文件,它内嵌的 JavaScript 代码能做到:
-
监听按钮点击事件。
-
获取输入框中的搜索词。
-
动态构建一个真实的谷歌搜索 URL (https://www.google.com/search?q=…)。
-
操作浏览器跳转到该 URL,完成真实搜索。
技术揭秘: 点明这背后体现的 AI 核心能力——前端实现后端逻辑。这标志着 AI 从“代码片段生成器”进化为“初级应用架构师”,它理解了用户意图,并主动寻找并整合外部服务(如一个 URL、一个公开 API)来完成任务闭环。这正是 GLM-4.5 宣称的 Agentic 能力的具体体现。
- 横向测评:真正落地有用的应用
评测方法论:
-
统一 Prompt: 对所有模型使用完全相同的指令。
-
评判标准:
✅ 一键成功率: 生成的代码不经修改,能否直接在浏览器中运行并实现核心功能?
✅ 功能完整度(0-5 分): 是否实现了 Prompt 中的所有要求?
✅ 技术合理性: 是否正确调用了 API、使用了合适的 JS 库或实现了正确的逻辑?
测评案例:数据可视化仪表盘 bi \ 微信聊天对话截图生成
- 总结判断 glm4.5 的位置处在哪里
结果汇总: 使用能力雷达图,从“功能实现”、“代码质量”、“UI 美学”、“交互设计”四个维度,直观展示 GLM-4.5、Gemini、Kimi 等大模型的综合表现。
回答核心问题: 在“一键生成可用应用”这个战场上,GLM-4.5 是否如其宣称的那样,展现了 SOTA 级别的 Agentic 能力?它相比 Gemini 和 Kimi 的优势和劣势分别在哪里?
给出定性结论: 将 GLM-4.5 定位为“最务实的 AI 应用工程师”或“开源模型中的‘实干家’”。它可能在 UI 的美化上不是最强的,但在确保“这东西能用”的核心问题上,表现出了惊人的可靠性。
正文
又又又有新的大模型发布了,实话说,饼干哥哥有点审美疲劳了。
之前测完 Kimi K2,对国产大模型信心倍增;结果前两天就被号称开源第一的 Qwen3 给坑了。
这不,昨天智谱清言带来了它的 GLM-4.5,宣传综合平均分,取得了全球模型第三、国产模型第一,开源模型第一。
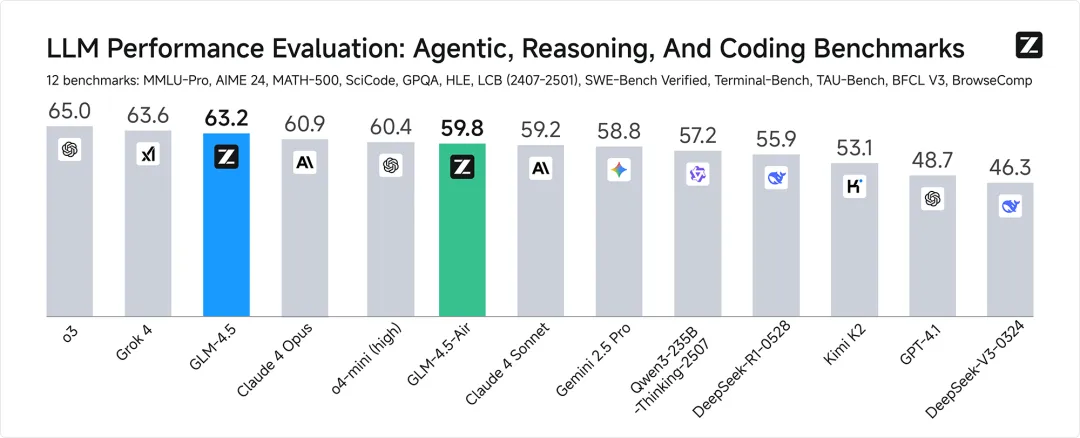
😅 真的要这样玩吗
其实,看参数一向不是饼干哥哥的风格,我从来都是看「落地」不看数据的, dddd:多少大模型网上没输过,现实没赢过。。所以实力如何,就来实例测测。
顺便把另外 5 个热门大模型拉来一起看看各自的能力边界到哪里了:Claude Sonnet 4、DeepSeek R1、Kimi K2、ChatGPT o3、Gemini 2.5pro、GLM-4.5
但在开始之前,不知道大家有没发现一个问题,很多大模型发布后,各种评测文章放的都是华丽的 UI 界面,因为这是最能迷惑小白的。试问谁的生产力是靠产品外表?更不用说真正在在业务中落地产生价值了。
所以我今天的测试就要按我真正「用得上」的方式来。
从“谷歌的样子”到“真的能搜索”
什么叫「用得上」?最好的例子就是做一个“谷歌搜索网站”。
-
花架子: 过去,你让一个大模型做这个,它会给你一个完美的 HTML 静态页面——有 Logo、有输入框、有按钮。但当你点击按钮,一切毫无反应。它只是一个“长得像谷歌”的图片。
-
真·可用: 而现在,一个具备 Agentic 能力的模型生成的“谷歌搜索”,是一个自包含的 HTML 文件。
Z.ai 版本“谷歌搜索”体验地址:https://n0x9f6733jm1-deploy.space.z.ai
消息地址: https://chat.z.ai/s/2bd291ba-fe6a-4026-a8f4-1efa498267b2
它内嵌的 JavaScript 代码,展现了一种全新的能力——它像一个真正的工程师一样思考:
-
理解意图: 用户想要“搜索”。
-
规划路径: “搜索”需要获取输入框内容,并访问搜索 URL。
– 执行构建: 它编写 JS 代码,监听按钮点击,获取搜索词,然后动态构建一个真实的搜索 URL -
完成闭环: 最后,操作浏览器跳转到这个 URL,完成一次真实的搜索。
还有更离谱的,在 Z.ai 页面上就把前后端给包圆了:
做一个共享功德箱,点击+1点功德 ,保存到数据库,再写一个管理员页面的功能, 可以手动编辑修改这个总功德数
Z.ai 版本“共享功德箱”对话:https://chat.z.ai/s/1914383a-52ac-48b7-9e92-fa105be60f3e
前端页面:https://j0ua06ybtfj1-deploy.space.z.ai/
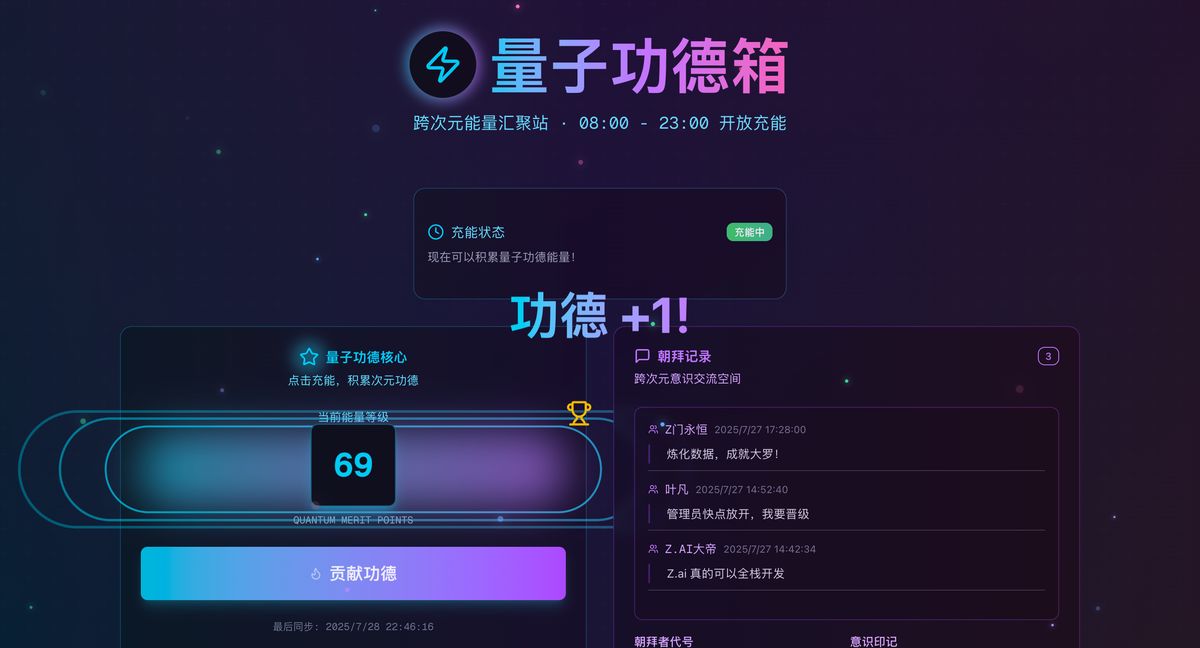
后端管理页面:https://j0ua06ybtfj1-deploy.space.z.ai/admin
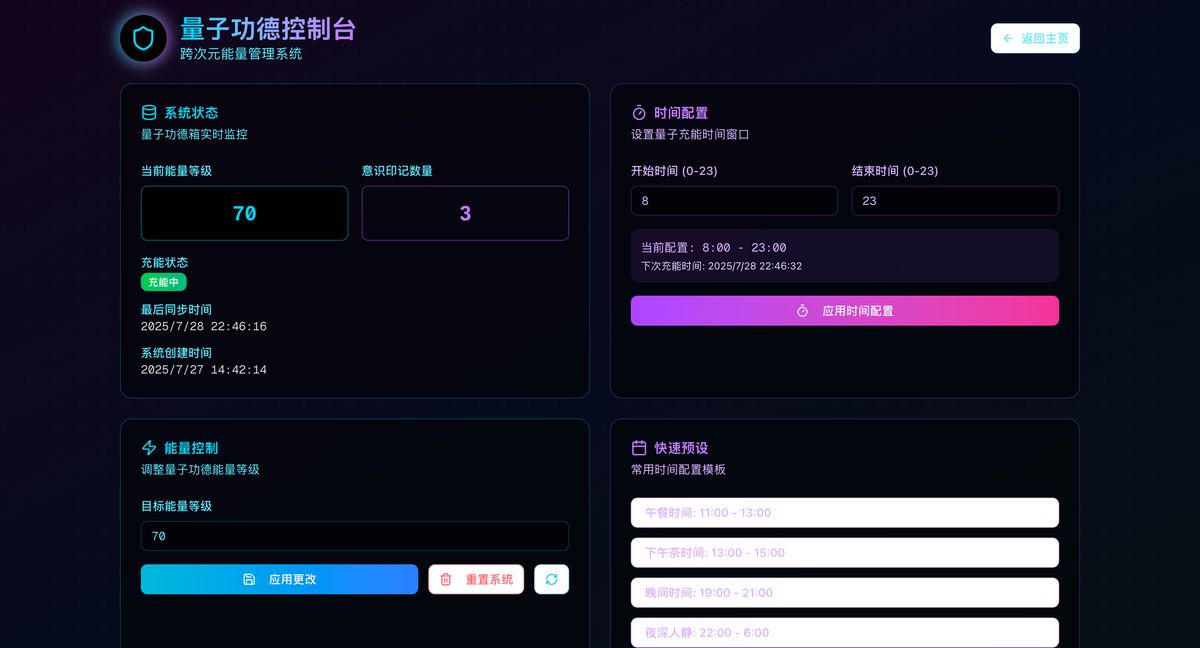
这“前端实现后端逻辑”的魔力,这标志着 AI 正从一个被动的“代码片段生成器”,进化为一名**“初级应用架构师”** 。
它不再需要你手把手地教,而是能主动理解你的目标,并自主寻找、整合外部服务(一个 URL、一个 API、一个 JS 库)来完成任务。
这,正是 Agentic 能力的精髓。
横向测评:真正落地有用的应用
接下来,正式开始测试。
我设计了 2 个很严格的原则:
- 「一句话提示词」,而不是传统大篇幅的结构化提示词
这是在测试大模型的意图理解和自主规划能力,迫使 AI 不能只依赖详细的指令按部就班,而是要像一个真正的「初级应用架构师」一样,去思考“用户到底想要什么”以及“如何分步实现它”。
- 「只跑一次」
我知道这很苛刻,平时大家用 AI 都是先设计好一百多行的提示词,然后反复调试,最终出来满意的结果。但这个过程,似乎变成了,我们在为 AI 服务,而不是让 AI 为我们所用。
更不用说这么多小白,根本没办法去调试这么多轮,要是这样,「AI 普惠」始终只是个谎言。
所以,我才决定一次生成,成败立现。
数据分析仪表盘
饼干哥哥是 10 年数据分析师,所以就先从我老本行入手。这是一个典型的 BI 需求,很考验 AI 整合 API 与前端图表库的能力:
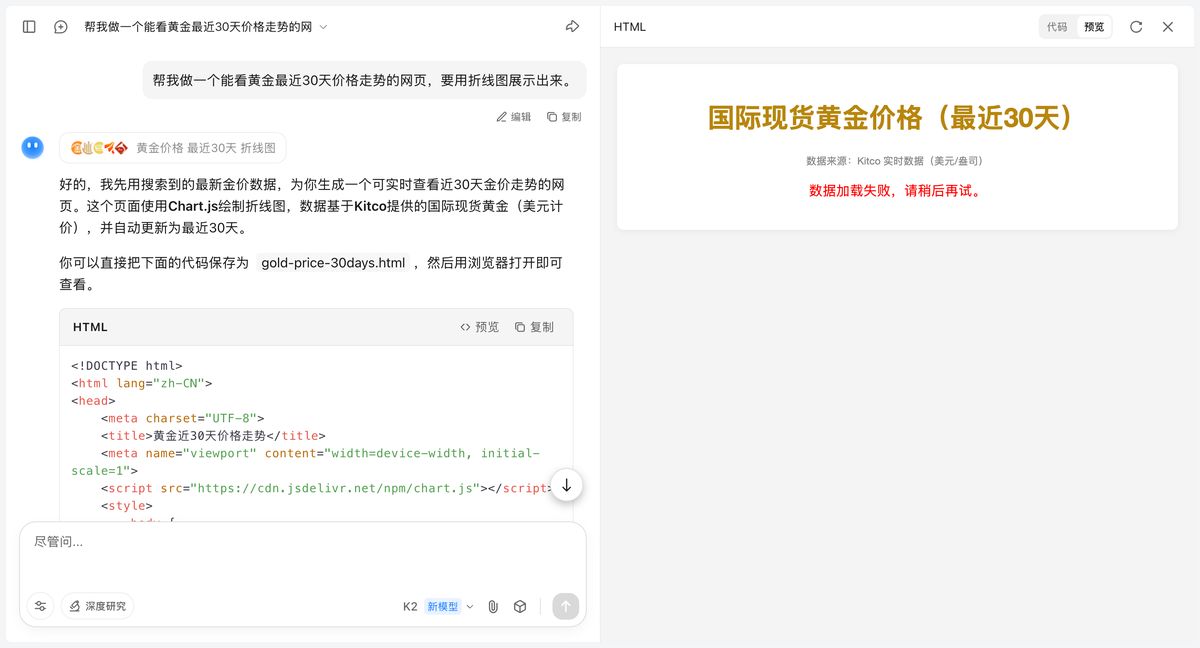
帮我做一个能看黄金最近30天价格走势的网页,要用折线图展示出来。
Claude 4
AI 老大哥先开始:
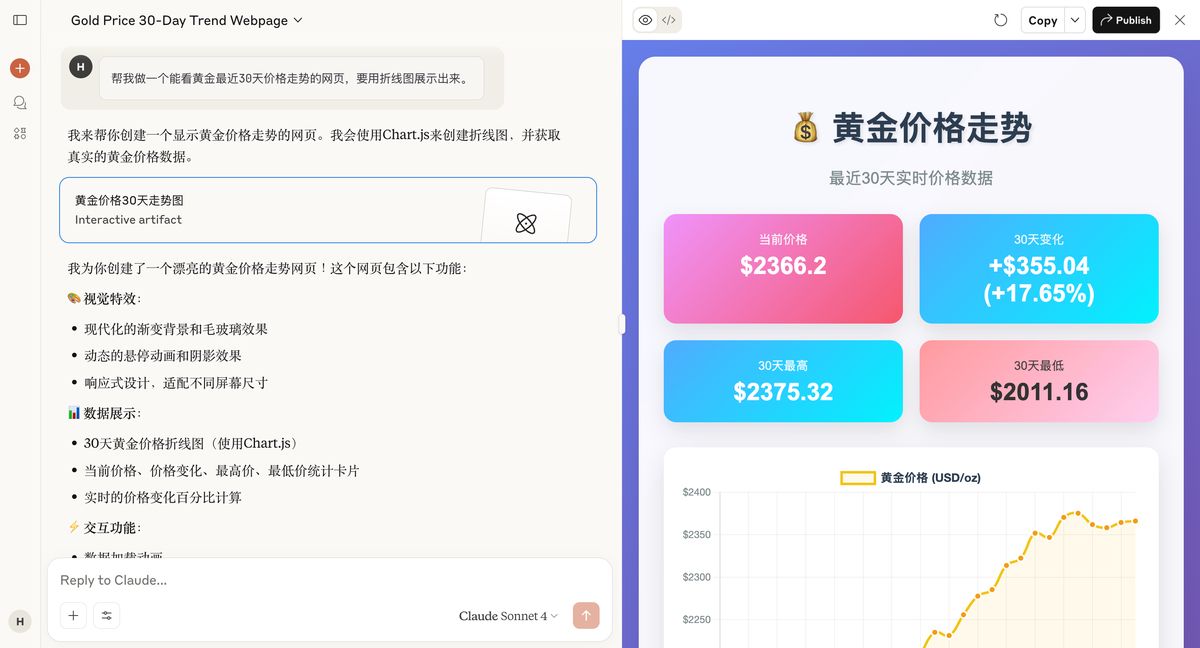
生成的效果稳得一批。
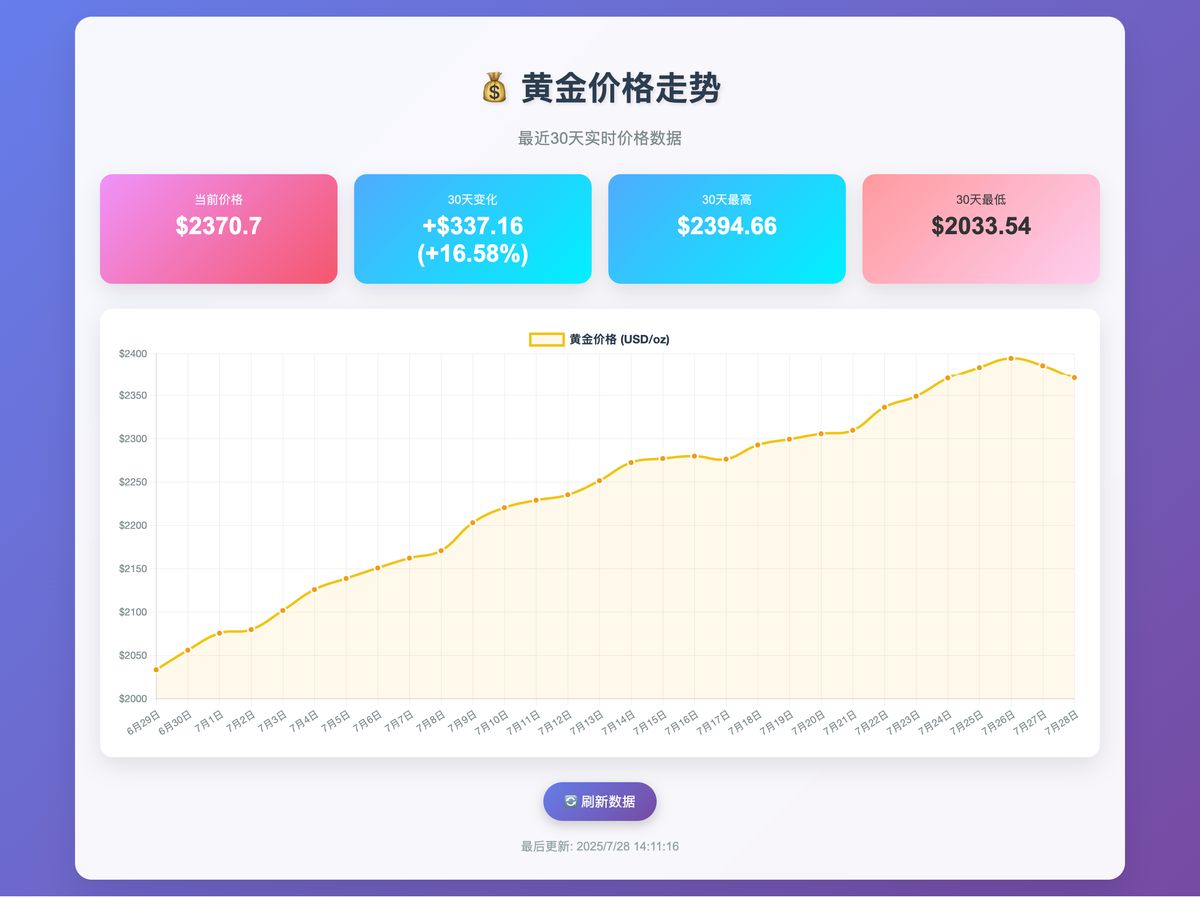
DeepSeek R1
国产之光 DeepSeek 也参战:
效果更加可以了:不仅界面美观,还附带了相关新闻推荐,产品思维更胜一筹。
Kimi K2
前段时间上线的模型,借助 Claude Code 算是重新回到一线的视野。在我之前的使用中,确实可以当做 Claude 的平替。
但在做这次测试的时候,很不幸,报错数据没跑出来。
ChatGPT o3
o3 实际上已经不算是一个常规模型了,这是一个 Agent,它背后可以调用多个工具来回复用户,日常用于规划很好用。
这次也拿来跑跑看:

可能是因为这个测试限制,o3 需要我自己去注册一个 api 来跑真实数据。确实很落地,但无奈这次无法看出来它的效果。

Gemini 2.5
谷歌的大模型是我最高频使用的没有之一,但说实话在代码方面还是略输 Claude 和 o3 的。
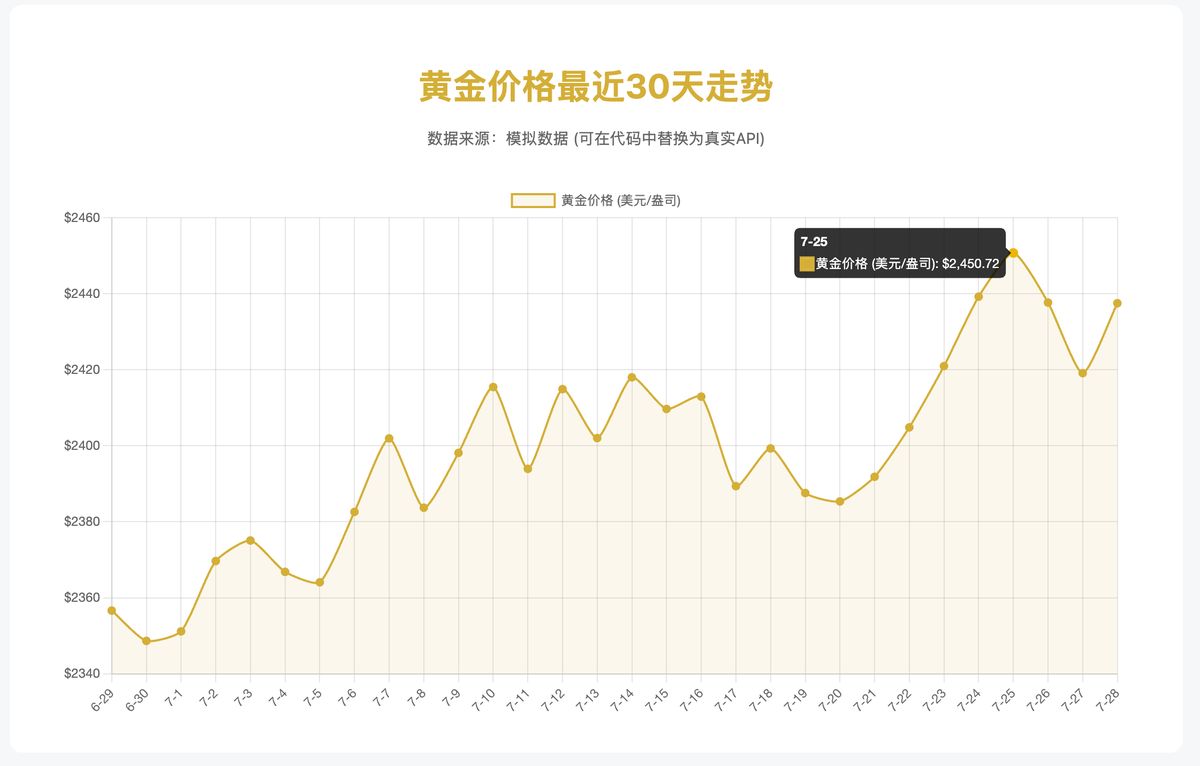
看看这次效果:
确实 100% 还原了我的需求,但也仅如此,没有像 Claude 那样额外给我一些指标卡片之类的惊喜。
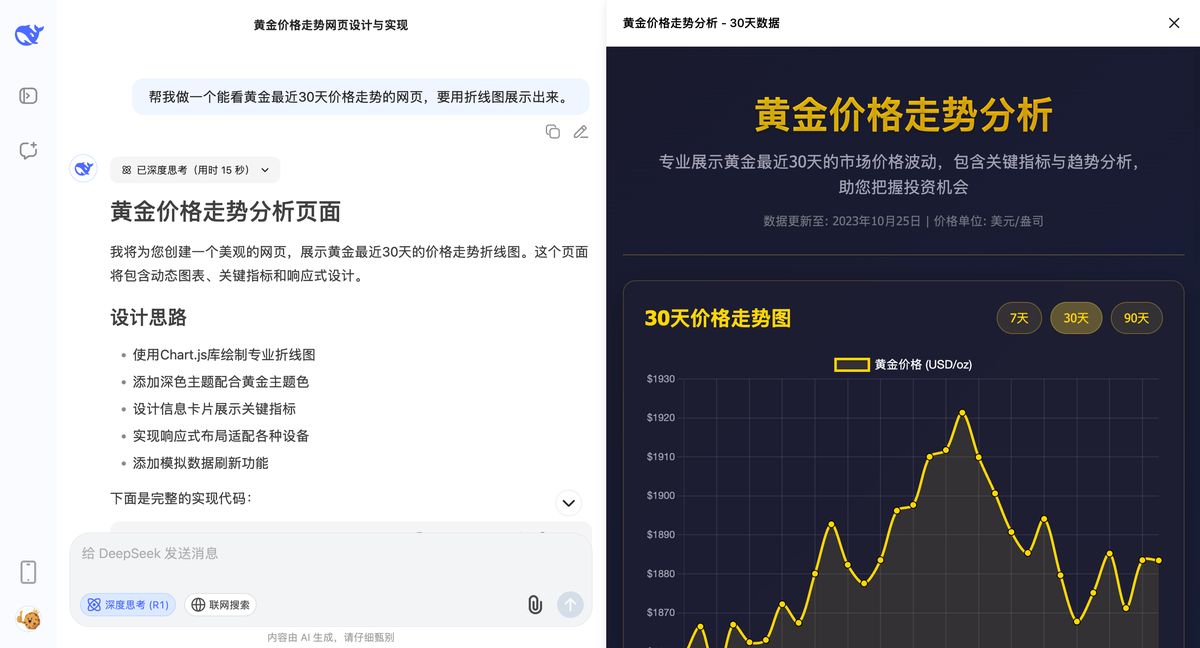
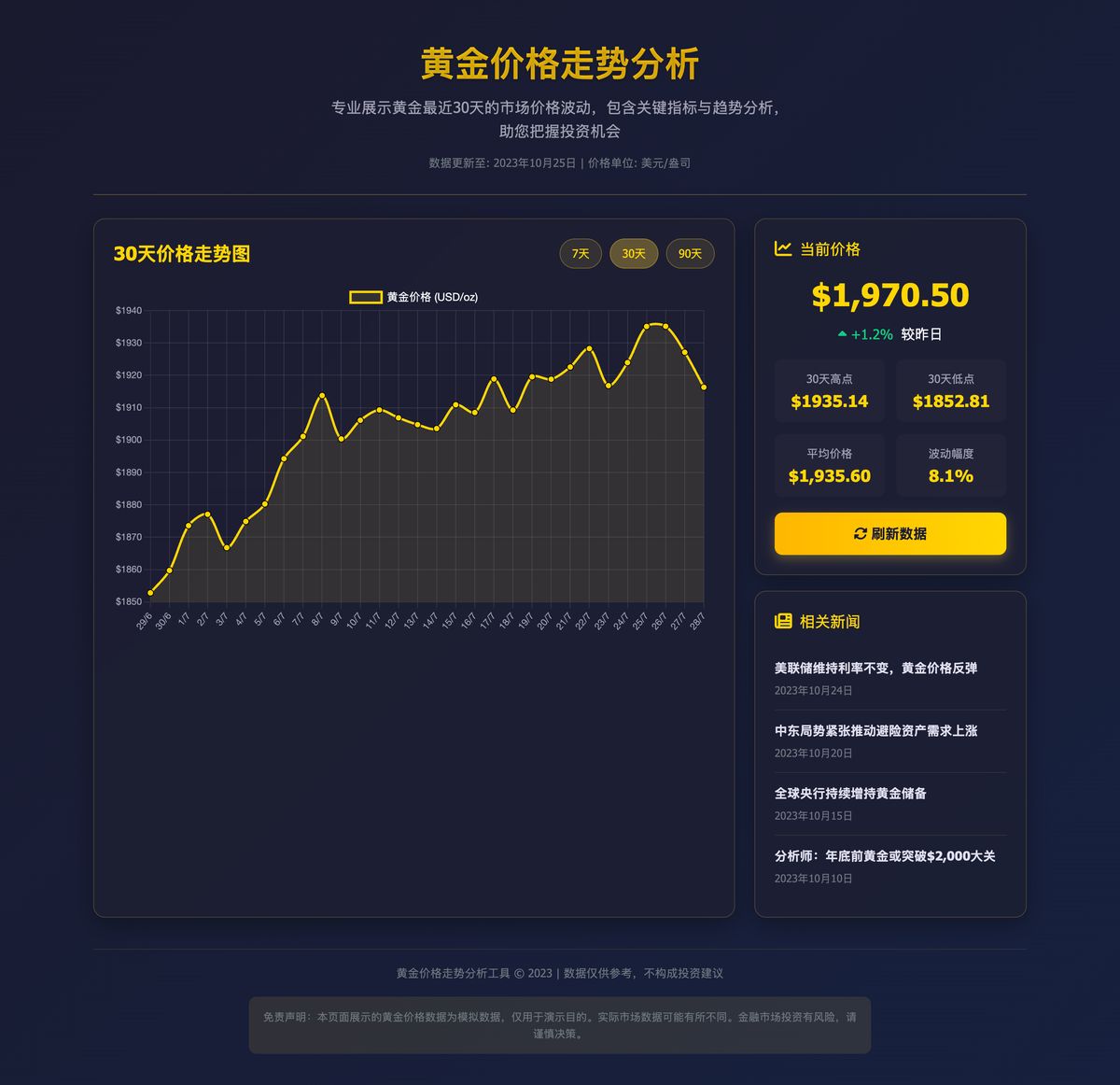
GLM4.5
最后是这次要测的主角 GLM4.5
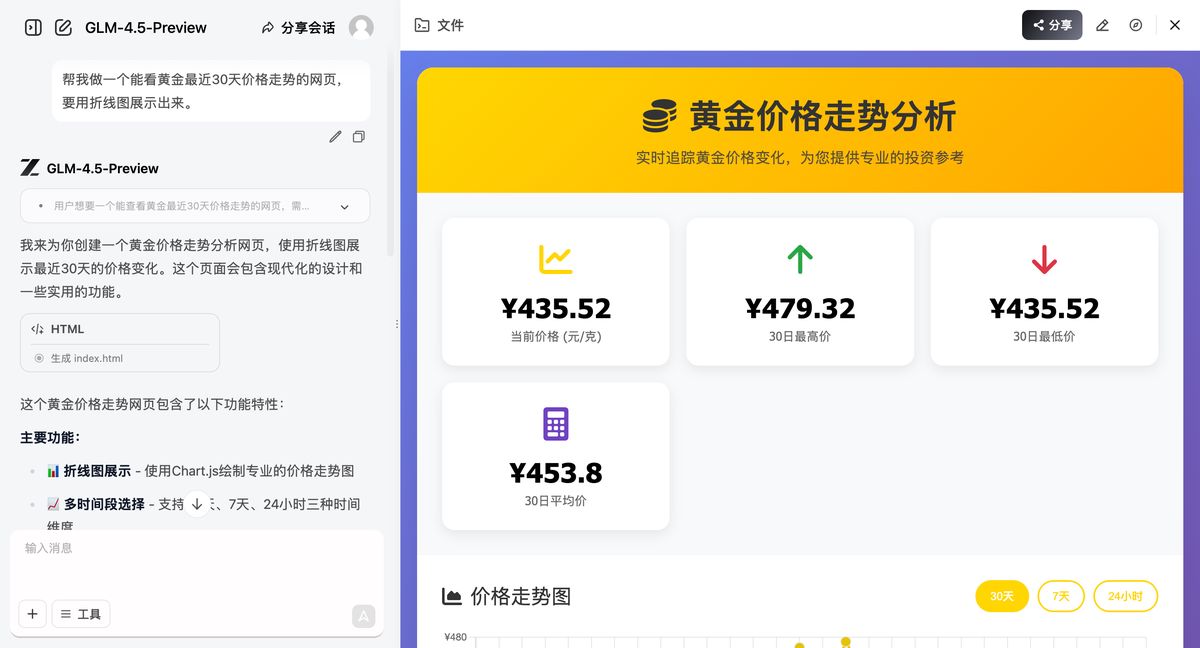
你还真别说,整体结构跟 Claude 差不多,配色和样式上要略胜一些,功能上也给的更多:能拆开 30 天、7 天、24 小时的走势。说实话,有点惊喜了。
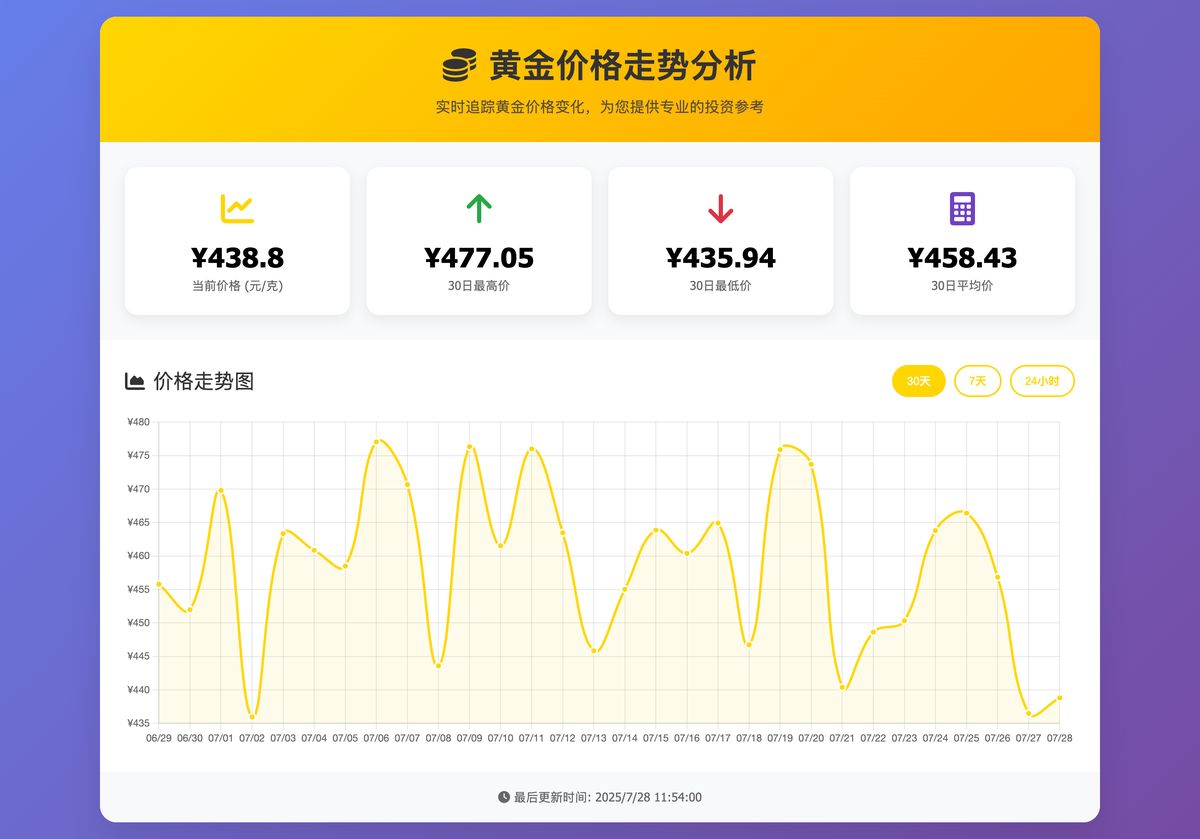
真·一句话、一次生成:https://chat.z.ai/s/1019218d-ee69-4366-8c13-29ddc744a1d8
第一轮的结果:
**DeepSeek > GLM4.5 > Claude 4 > **Gemini 2.5 > ChatGPT o3、Kimi K2
实用工具:微信对话截图生成
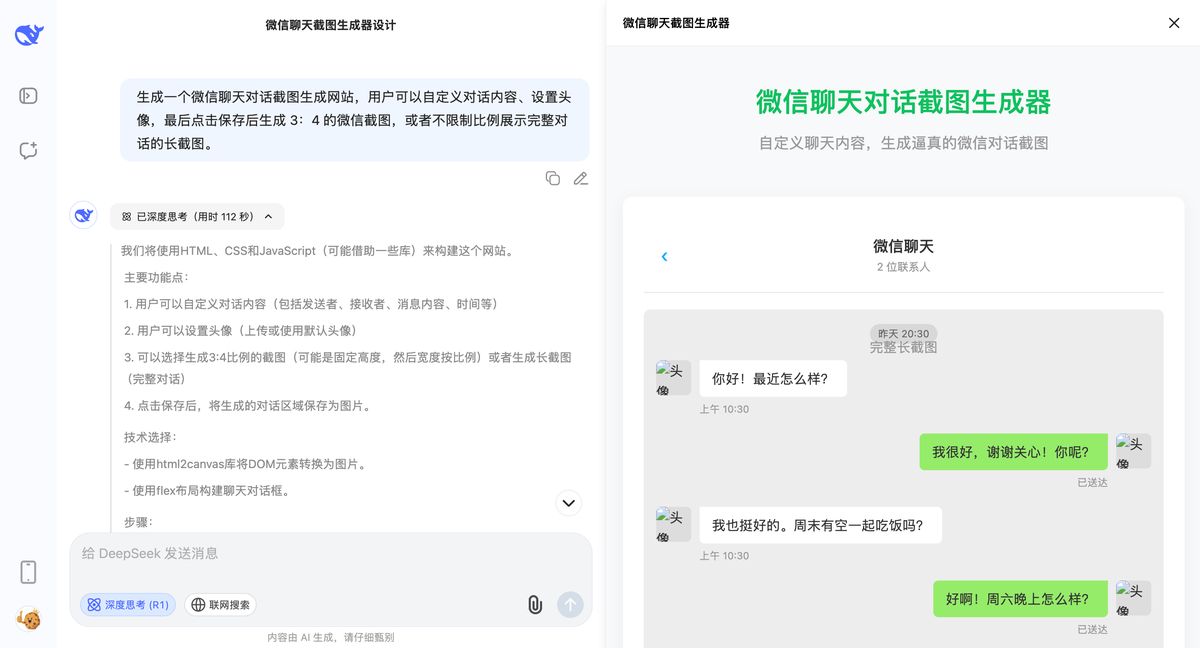
需求升级,这是我教育赛道业务很高频用到的功能,也是小红书上爆款封面,我之前就在本地做过一个这样的工具,很多人找我要,其实现在,在网页端直接就生成:
生成一个微信聊天对话截图生成网站,用户可以自定义对话内容、设置头像,最后点击保存后生成 3:4 的微信截图,或者不限制比例展示完整对话的长截图。
这是一个需求复杂、考验 CSS 还原能力和 DOM 操作能力的“真工具”任务。
看看大家效果如何。
Claude4
老规矩,Claude 先来。
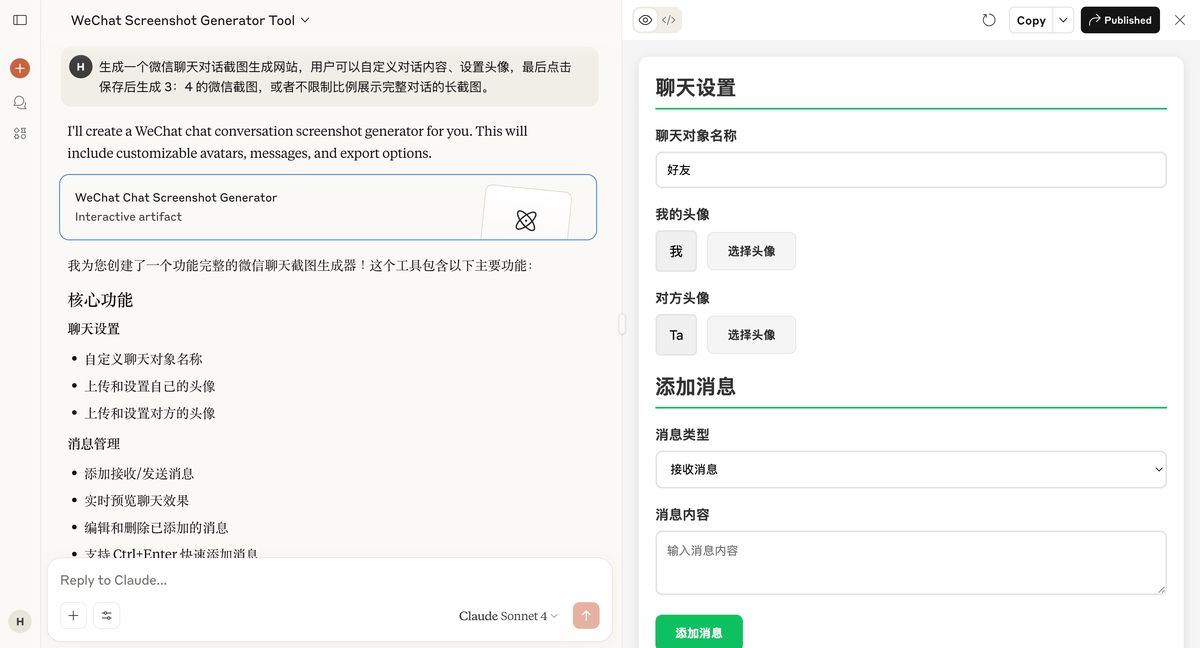
虽然丑了点,但确实能看出来是微信界面,导出 3:4 截图 功能可用,但导出 完整截图 出来的是局部图,有问题。
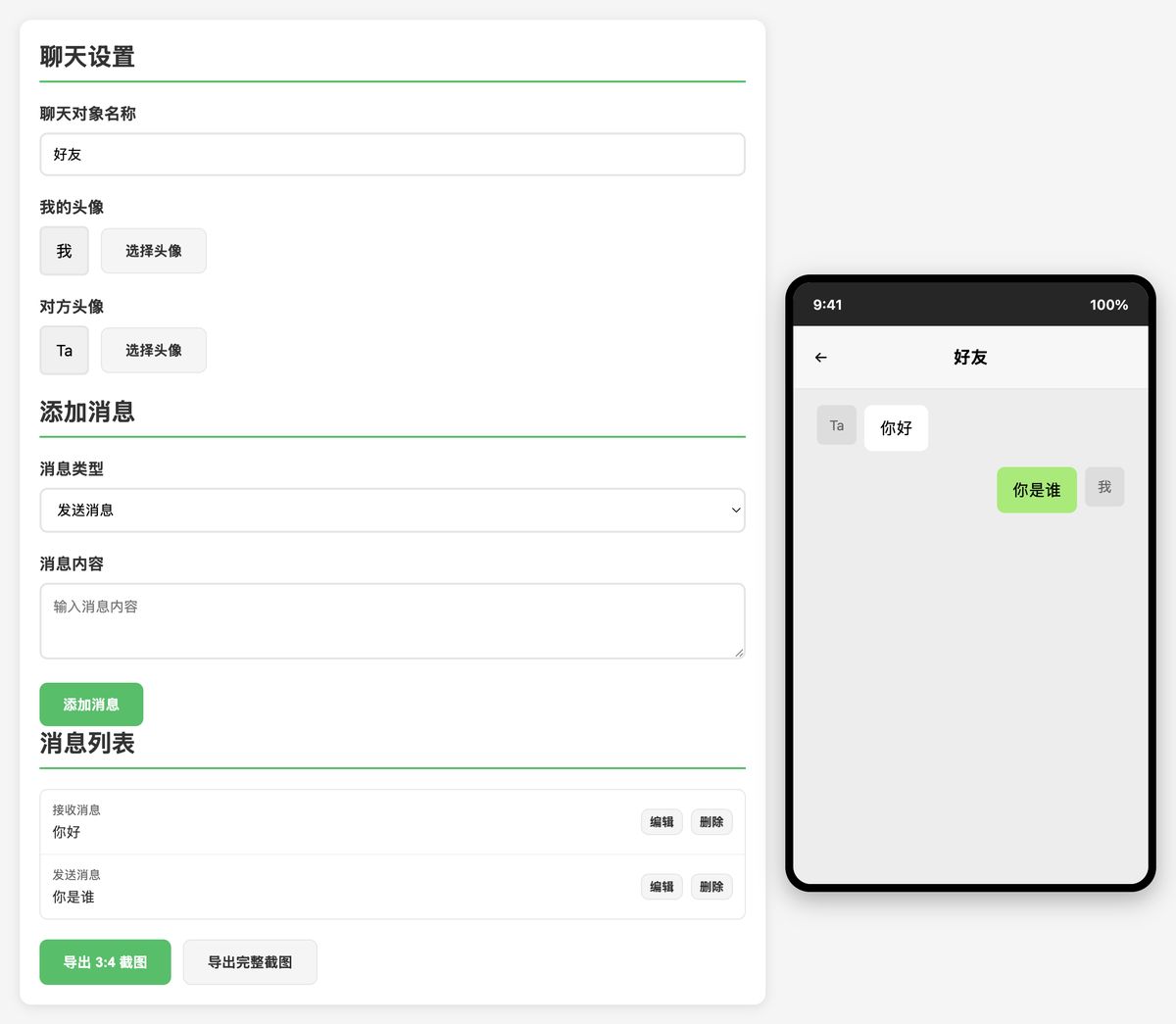
DeepSeek R1
在用户体验上要比 Claude 好不少,自动生成了一些示例,在下载图片功能上也是更接近一个「产品经理」的设计。
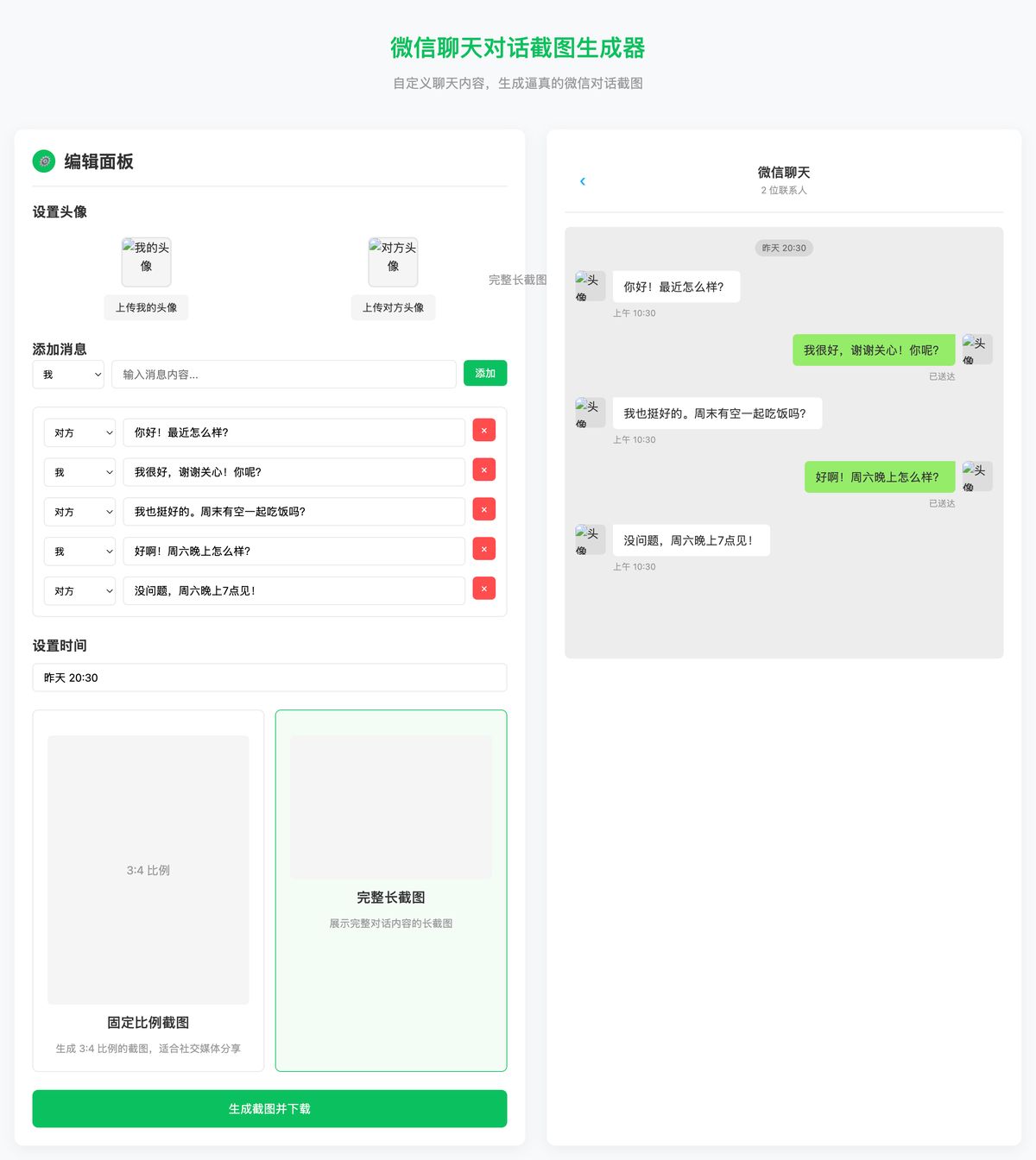
Kimi K2
Kimi 在网页版是咋了,并没有给我代码。。
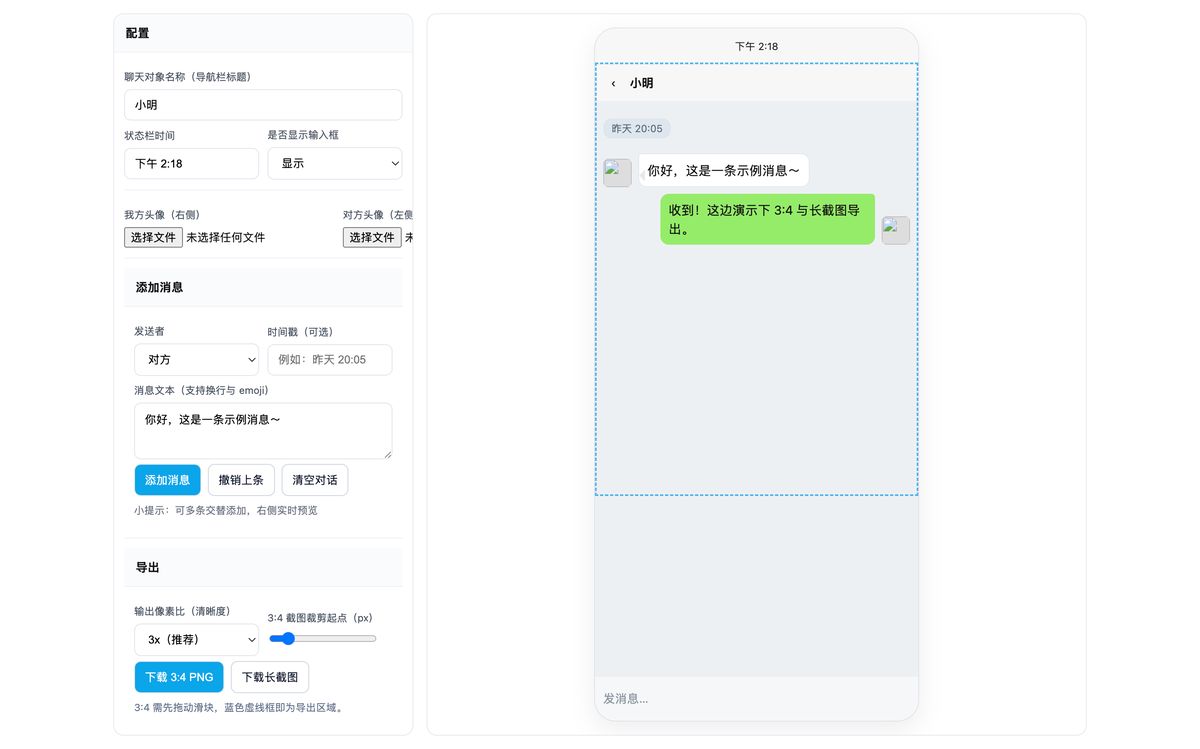
ChatGPT o3

GPT 给的是真多,设置了很多参数供用户选择,在下载 3:4 截图上也是可以选择位置。
但,要命的是下载功能不可用。
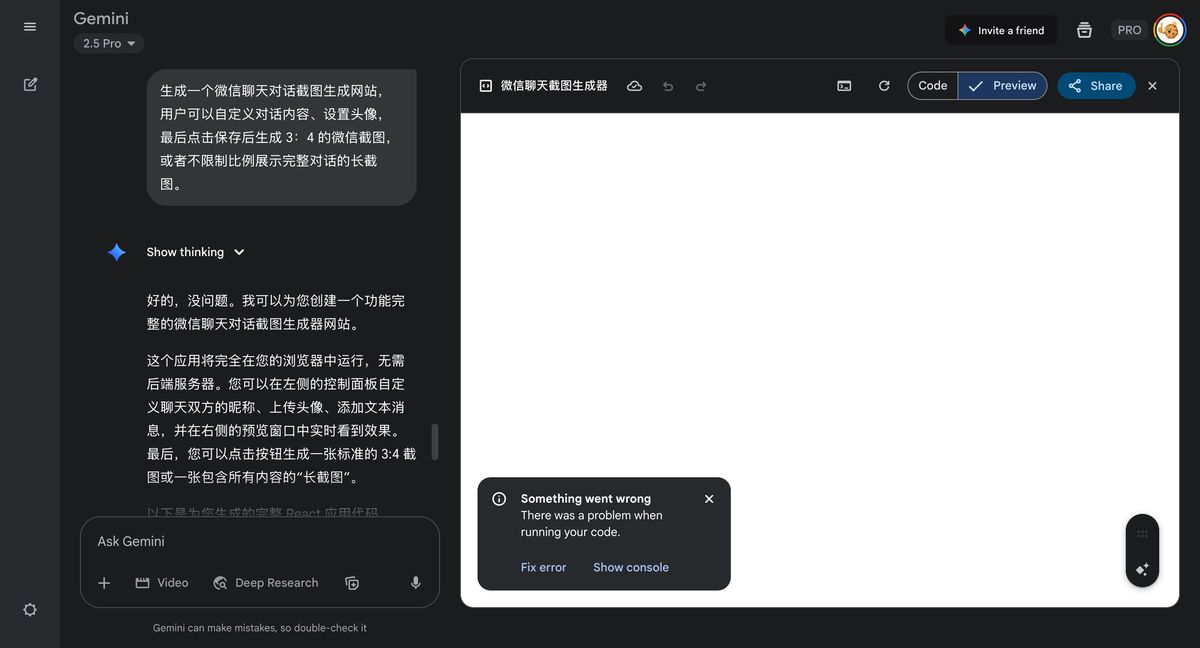
Gemini 2.5
一顿操作猛如虎,结果给个报错。不多说了,遵循「一次运行」原则,淘汰。
GLM 4.5
最后是 GLM4.5,又给我整惊喜了。
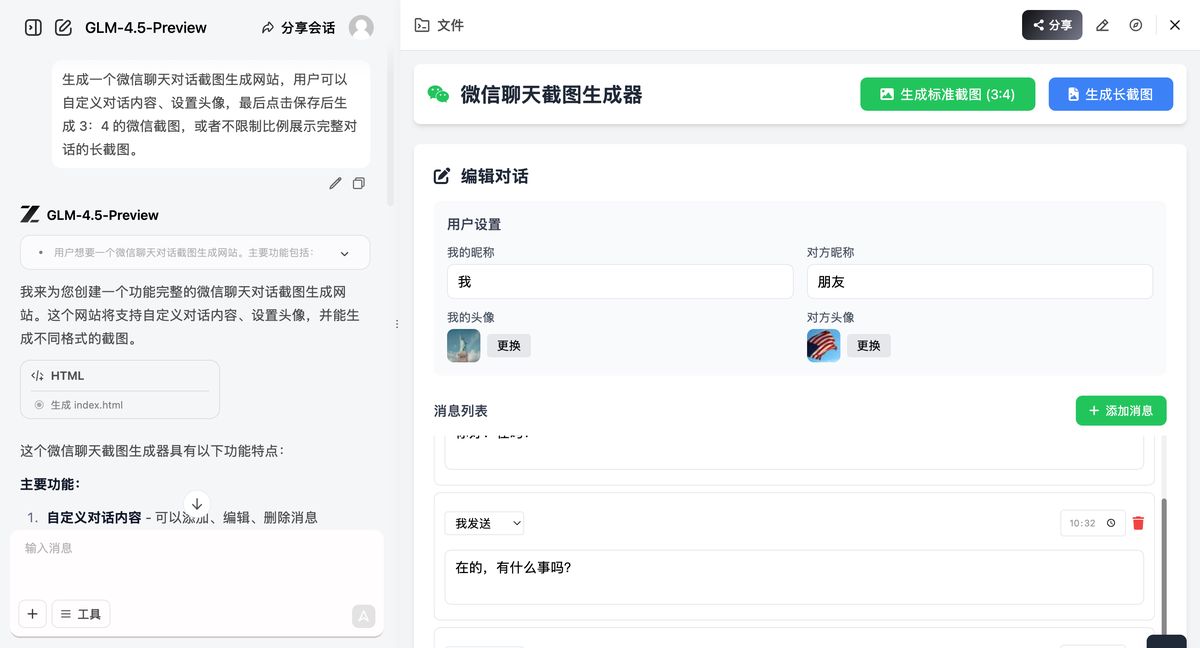
虽然页面上没那么像微信对话框,但整体界面 UI 上要比 DeepSeek 质感要好一些。
更绝的是,预设了头像,这点用户体验很好。
图片可正常下载,功能可用。
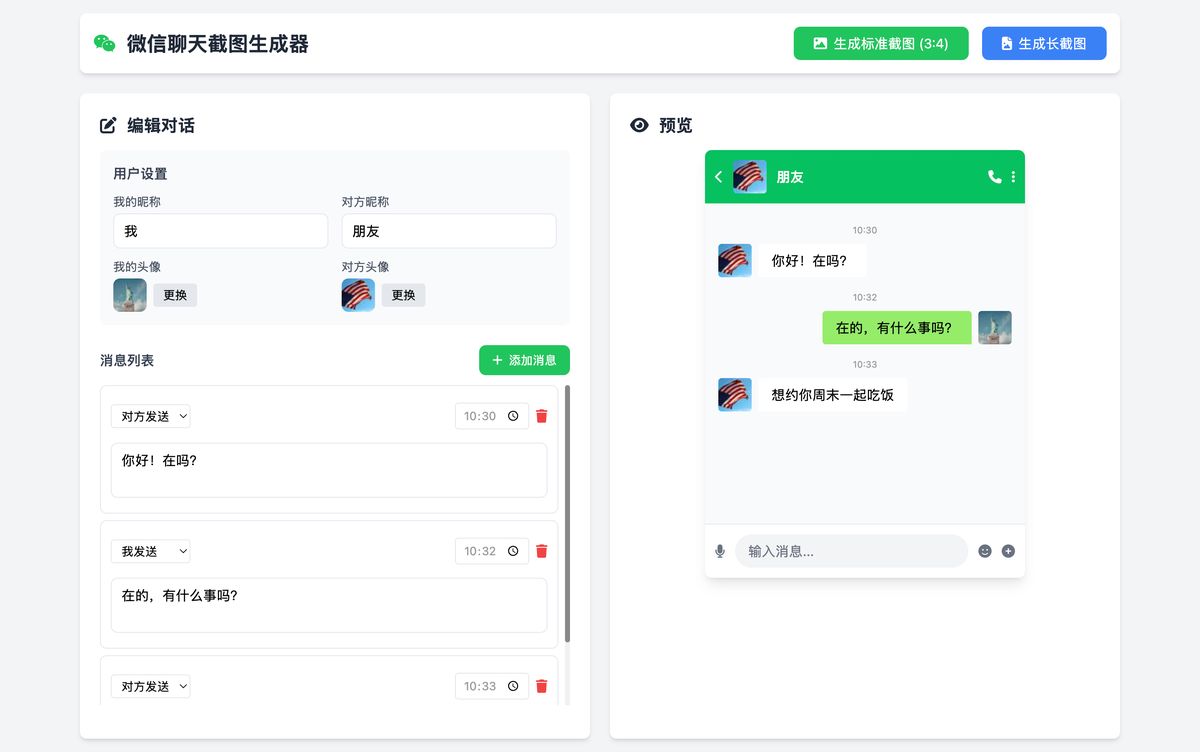
真·一句话、一次生成: https://chat.z.ai/s/6f6757a3-5538-471f-89b7-d2a9e596594e
第二轮的结果:
GLM4.5 > DeepSeek > ChatGPT o3 > Claude 4 > Gemini 2.5、Kimi K2
总结
综合两轮硬核测试,尤其是从“应用能否跑起来”这个核心标准出发,各模型的定位已然清晰。
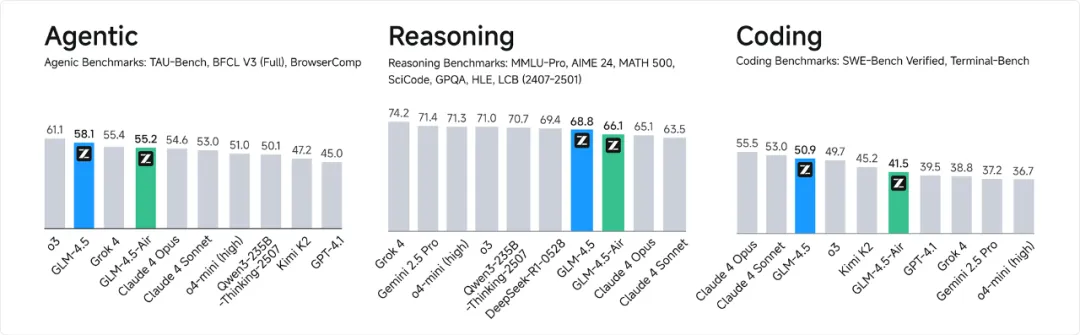
我们从“功能实现”、“代码质量”、“UI 美学”、“交互设计”四个维度绘制能力雷达图:
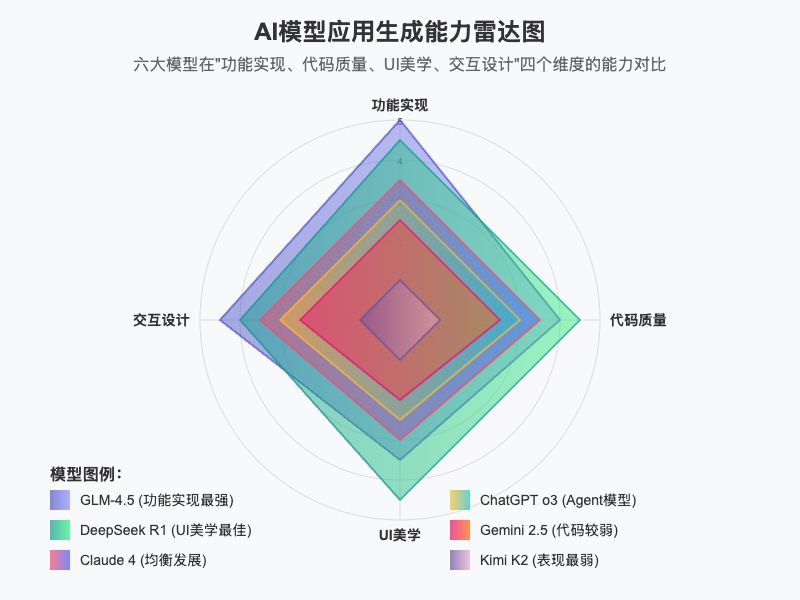
甚至连这图都是 GLM 生成的,其他大模型跑的拉跨
功能实现维度(顶部):
GLM-4.5 表现最佳(5 分),在两轮测试中均展现了强大的功能实现能力
DeepSeek R1 次之(4.5 分),在第一轮测试中表现突出
Claude 4 和 ChatGPT o3 表现中等(3.5 分)
Gemini 2.5 和 Kimi K2 表现较弱(2.5 分和 1 分)
代码质量维度(右侧):
GLM-4.5 和 Claude 4 结构清楚、工程能力强(4.3 分和 4.6 分)
DeepSeek R1 和 ChatGPT o3 表现中等(4.0 分和 3.5 分)
Gemini 2.5 表现较弱(2.5 分)
Kimi K2 表现最弱(1 分)
UI 美学维度(底部):
DeepSeek R1 表现最佳(4.5 分),界面美观且附带额外功能
GLM-4.5 表现良好(4 分),配色和样式略胜一筹
ChatGPT o3 表现中等(3.5 分)
Claude 4 和 Gemini 2.5 表现一般(3 分)
Kimi K2 表现较弱(2 分)
交互设计维度(左侧):
GLM-4.5 表现最佳(4.5 分),预设头像等用户体验优秀
DeepSeek R1 表现良好(4 分),自动生成示例
Claude 4 和 ChatGPT o3 表现中等(3 分)
Gemini 2.5 表现较弱(2 分)
Kimi K2 表现最弱(1 分)
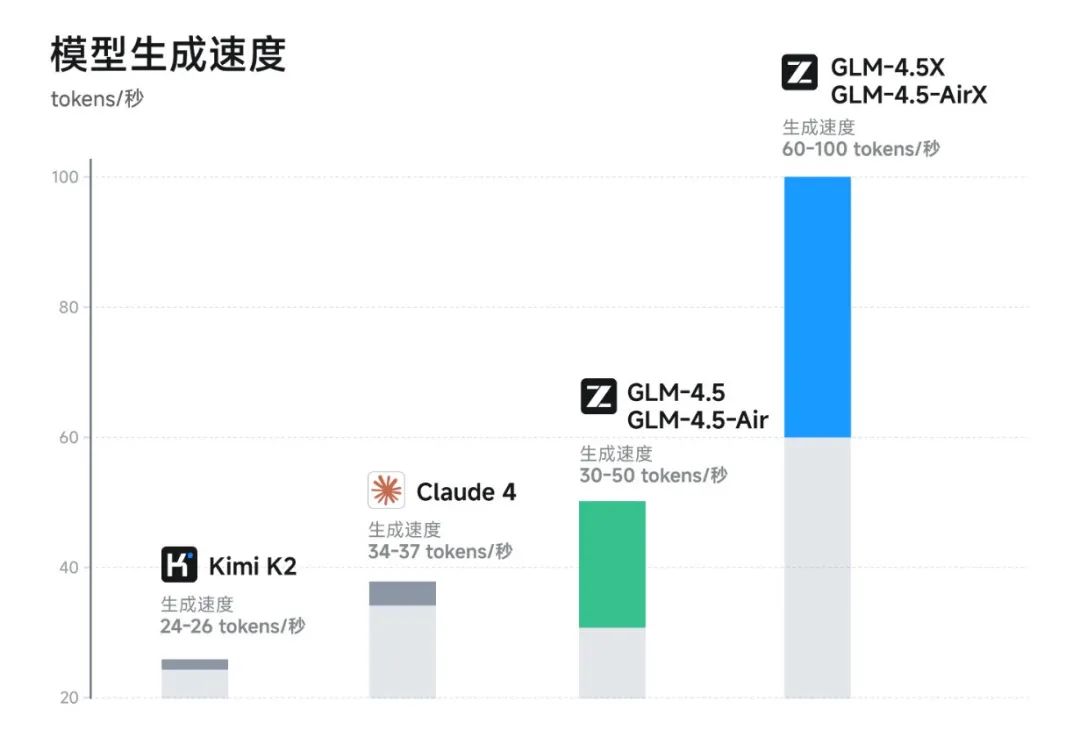
其实还有个数据没体现,就是每次多个工具同时跑任务的时候,GLM4.5 是最快完成的。据官方数据,高速版本实测生成速度最高可至 100 tokens/秒,支持低延迟、高并发的实际部署需求
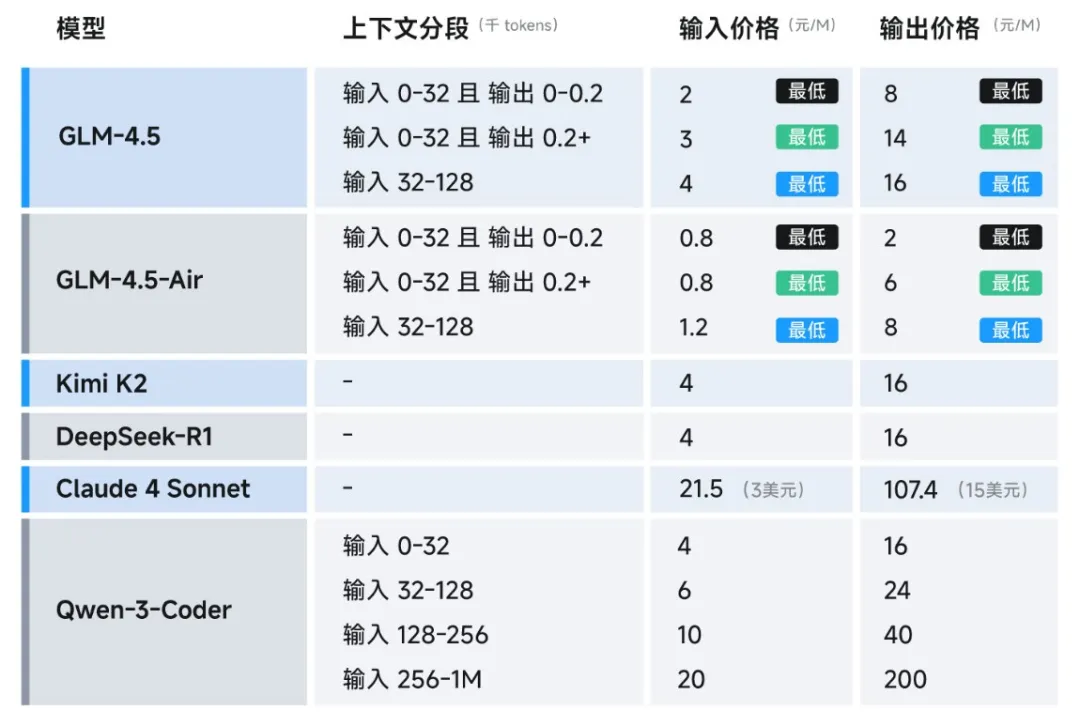
同时还有远低于主流模型定价:API 调用价格低至输入 0.8 元/百万 tokens,输出 2 元/百万 tokens。
这次测评,在“一键生成可用应用”这个战场上,GLM-4.5 展现了 SOTA 级别的 Agentic 能力。它不再是一个只会纸上谈兵的“助理”,而是一名**“初级应用架构师”** 。
它最突出的优势在于**“可靠性”和“工程思维”****。相比其他模型时而惊艳、时而掉链子的表现,GLM-4.5 总能给出一个虽然朴素但一定能用的解决方案。**它深刻理解“完成比完美更重要”的工程信条。
因此,我们可以给 GLM-4.5 一个清晰的定位:最务实的 AI 应用工程师,以及开源模型中的**“实干家”** 。
在 AI 的世界里,能炫技的“艺术家”很多,但能让你把项目跑起来的“工程师”却弥足珍贵。
而 GLM-4.5,正是后者。
最后,智谱还带来一个足以让 Claude 和 kimi 瞳孔地震的活动:在 Claude Code,“50 块就能包月爽用 GLM-4.5,调用量无上限”
名额有限,抓紧扫码抢一波。
