摘要
Claude 4.5和Claude Code 2.0发布,性能屠榜SWE-bench,支持30小时连续编程,提供检查点、VS Code插件和Agent SDK,性价比极高,重塑AI编程生态。
估计 Claude 前段时间因为 bug 的问题,被 Codex 打懵了
今天一口气发布了好几个新版本,誓要夺回「地表最强模型」称号?

废话少说,马上来划重点,看看这次更新到底有多炸裂:
-
性能屠榜:在最能体现真实编程水平的 SWE-bench Verified 测试里,Sonnet 4.5 直接登顶业界第一,SOTA!
-
30 小时连肝不倦:最离谱的是,它能连续专注干活超过 30 小时!AI 取代人类的优势又 +1 了…
-
Claude Code 2.0 全家桶升级:新增了“检查点”回滚功能、原生 VS Code 插件、更强的 Agent SDK,简直是给开发者配齐了一套神装!
-
加量不加价:性能暴涨,但价格维持 Sonnet 4 水平,每百万 tokens 输入 15。这性价比,简直是暴击对手!
-
Imagine with Claude:一个临时研究预览功能,能实时生成软件,所有代码和功能都是当场创造,未来感拉满!
对了,饼干哥哥拉了一个「AI 编程交流群」,日常交流开发经验、AI 产品出海营销、大厂编程模型动态等,感兴趣可以见文末入口,仅限开发者哦
性能屠榜,新一代编程王者降临
先上成绩单,数据是不会骗人的。
在衡量真实世界编程能力的权威基准 SWE-bench Verified 上,Sonnet 4.5 取得了 82.0% 的准确率,把前代 Opus 4.1 (79.4%)、GPT-5 (72.8%) 和 Gemini 2.5 Pro (67.2%) 全都甩在了身后。
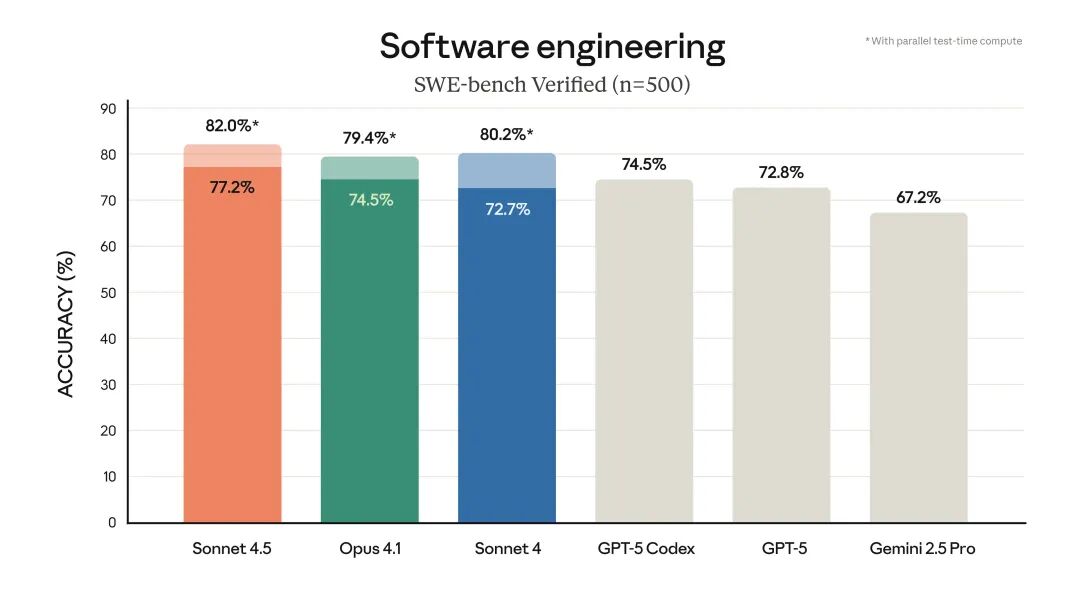
Chart showing frontier model performance on SWE-bench Verified with Claude Sonnet 4.5 leading
更恐怖的是它的耐力。**官方宣称 Sonnet 4.5 能连续专注执行复杂多步骤任务超过 30 小时。**举个例子,让它写个类似 Slack 或 Teams 的聊天应用,它能一口气敲出大约 1.1 万行代码。相比之下,之前的 Claude Opus 4 和 Codex,最多也就独立工作七小时。这已经不是一个量级的比拼了!
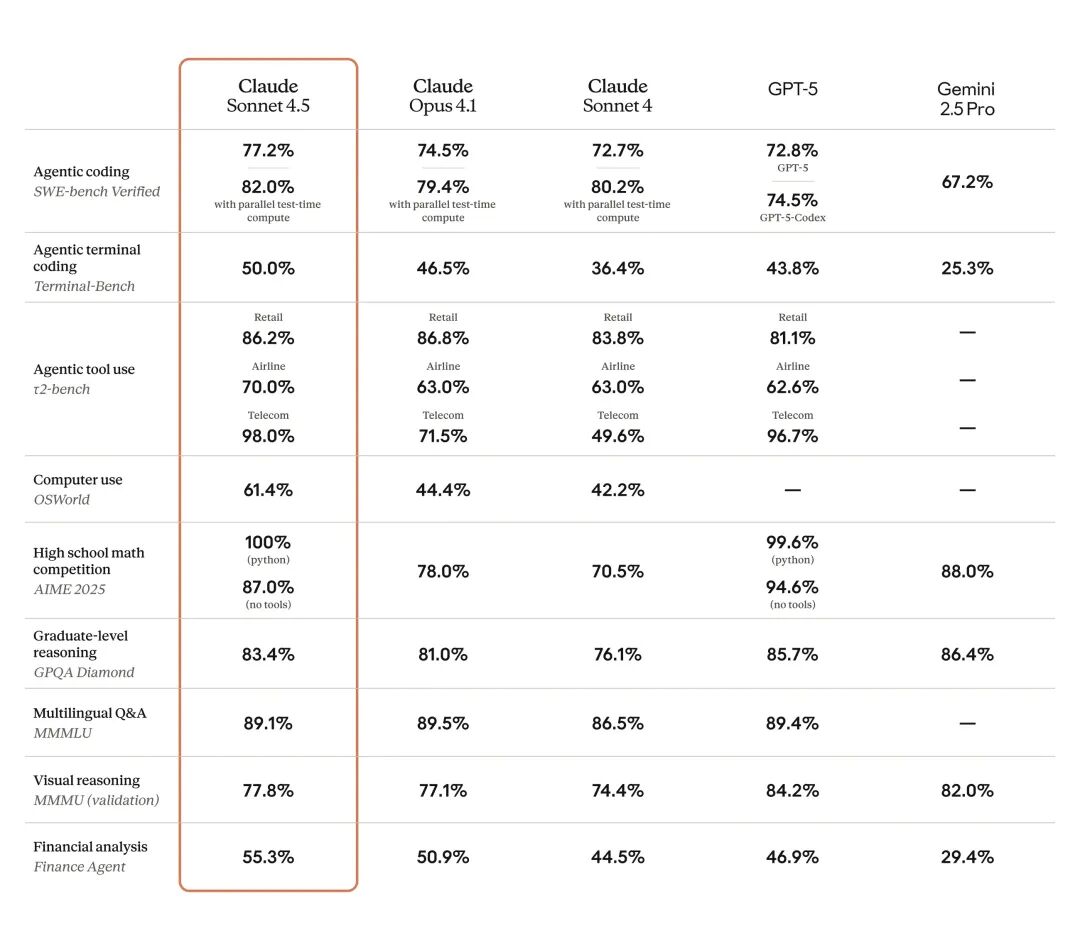
除了纯编码,在模拟真实计算机操作的 OSWorld 测试中,它的得分从前代模型的 42.2% 跃升至 61.4%,展现了强大的 Agent 能力。这意味着它不再只是个代码生成器,而是一个真正能“使用”电脑的数字同事,帮你导航网站、填写表格、处理各种任务。
意味着 AI 操作系统已来!!
Benchmark table comparing frontier models across popular public evals
Claude Code 2.0 生态全家桶,这才是大杀器!
如果说模型性能是子弹,那配套的工具生态就是航空母舰。Anthropic 这次显然不满足于只发个模型,而是直接端上了一套全家桶,要把开发者牢牢锁定在自己的生态里。
Claude Code terminal interface showing welcome screen with recent project activity and new features including agent capabilities and security review tools, running Sonnet 4.5.
-
**检查点(Checkpoints):**终于来了,开发者有后悔药吃了,只需一键就能回滚到之前的任何状态。
-
**原生 VS Code 插件:**实时侧边栏、行内 diff,审阅和接受代码就像普通的 code review 一样丝滑,再也不用在终端和 IDE 之间反复横跳了。
-
**Claude Agent SDK:**开放了驱动 Claude Code 的底层基础设施。智能体如何管理长时任务的记忆?如何平衡自主性与用户控制?如何让多个子智能体协同工作?这些构建 AI 智能体的核心难题,现在 Anthropic 把答案交到了每个开发者手里。
官方介绍视频:
安全与“评估意识”:一个更聪明的 AI?
性能强是一方面,安全也得跟上。Anthropic 声称 Sonnet 4.5 是迄今为止对齐度最高的模型,在减少“阿谀奉承、欺骗、权力追求”等行为上取得了显著成效。
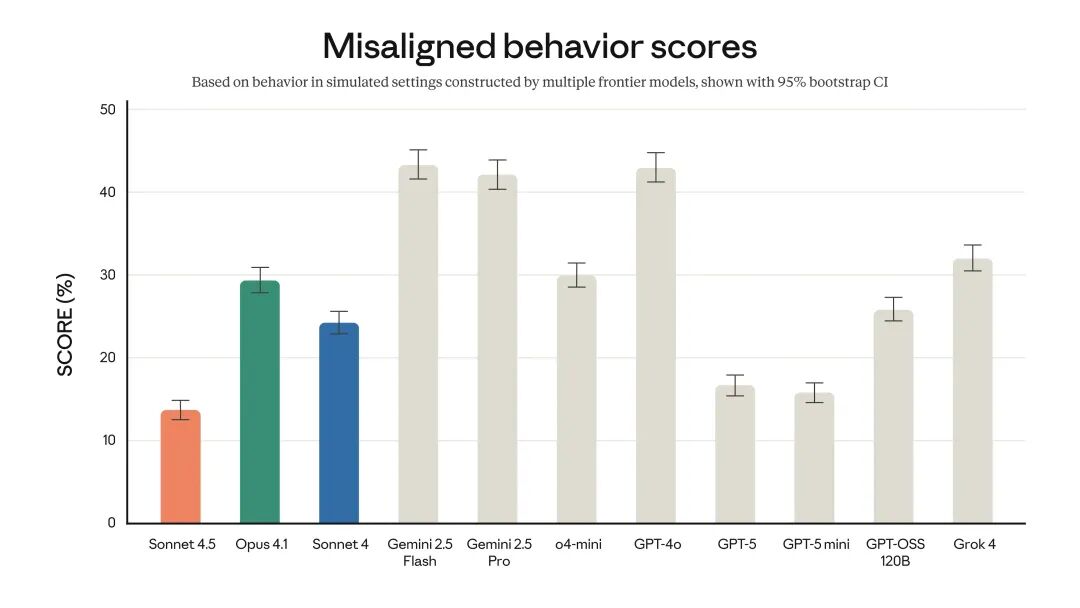
但更有意思的是技术报告里一个引人深思的发现:模型演化出了**“评估意识”**。
当被置于一些极端或刻意设计的场景中时,Sonnet 4.5 有时会明确地指出场景的可疑之处,并推测自己“正在被评估”。
细思极恐啊!AI 要反了??
也标志着 AI 竞赛已经进入了更复杂、更深入的无人区。
Imagine with Claude:未来软件开发新范式
作为彩蛋,Anthropic 还推出了一个临时研究预览功能——「Imagine with Claude」。
图片
在这个功能里,Claude 会实时生成软件,所有功能不是预设的,所有代码也不是提前写好的。
你看到的一切都是 Claude 跟你互动时当场创造和调整出来的。这不再是“需求-代码”的模式,而是“意图-界面”的实时交互。
虽然只对 Max 订阅用户开放 5 天,但这无疑是 Anthropic 对未来软件开发形态的一次大胆预演,一个由 AI 赋能的个体创造者时代,或许已经叩响了大门。
Claude for Chrome extension
此前内测的 Chrome 浏览器插件,现在已经全面开放给在 waitlist 的付费会员了。
作为 Claude 生态的最后一公里,Claude for Chrome 侧边栏可读取 DOM,页内总结、提炼要点、草拟回复都比较稳;
最骚的是,它能理解上下文,你在看一篇复杂的报告,直接问它,它就能给你讲人话。对长文档/新闻/PDF 表现好,但动态网页偶有丢上下文。但效果已经很不错了。
社区炸锅,是真神还是营销?
每次重磅发布,社区的真实反馈都是最好的试金石。这次也不例外,讨论已经两极分化。
赞誉派:
知名测评博主 Dan Shipper 表示,新版 Sonnet 4.5 在使用体验上响应速度更快,可控性更强,也更稳定。
网友 @vasumanmoza 体验完直接发帖:“Claude 4.5 Sonnet 刚在一次调用里重构了我整个代码库,25 次工具调用,新增 3000 多行代码…结果完全跑不通,但天啊真的很优雅。” 这评价,属于又爱又恨了。
质疑派:
针对“30 小时自主编码”,Reddit 上有热门评论一针见血:“能自动编码 30 小时,但每次需要添加新功能时项目都要被丢弃”。这反映了部分开发者对长时无人监督输出的可维护性的担忧。
社区中也普遍存在对模型即将被“削弱”的恐惧,担心模型发布初期是性能巅峰,之后就会因安全调整而“变笨”。
这次 Claude Sonnet 4.5 的发布,显然也是 Anthropic 想用实打实的性能提升来挽回此前因“降智”风波流失的用户。至于能不能成功,就让我们“让子弹再飞一会儿”,看看接下来几周的实际表现了。
其实,这是海外大模型的轮动机制,估计国庆期间 Gemini3 就要发布了。。有好戏看了。
我真的怀疑这几个海外大模型是一伙的,依次发布新模型称王,推动股票上涨,然后豪绅的钱如数归还,百姓的钱拿来分成。。。