摘要
实战演示如何用Crawl4ai+Playwright MCP构建AI爬虫,解决动态加载、表格提取难题,并成功抓取亚马逊评论数据,为出海业务提供自动化数据采集方案。
上一篇文章我们介绍了 2025AI 爬虫的 4️⃣ 个工具,今天来做一个实战:用 Crawl4ai 做一次 AI 爬虫,看看是什么样子的
具体的介绍就不赘述了,大家可以看上一篇文章。
小试牛刀
先根据官方的代码安装起来:
# Install the package
pip install -U crawl4ai
# Run post-installation setup
crawl4ai-setup
# Verify your installation
crawl4ai-doctor
最后看到下图的样子,就证明安装、初始化成功了。
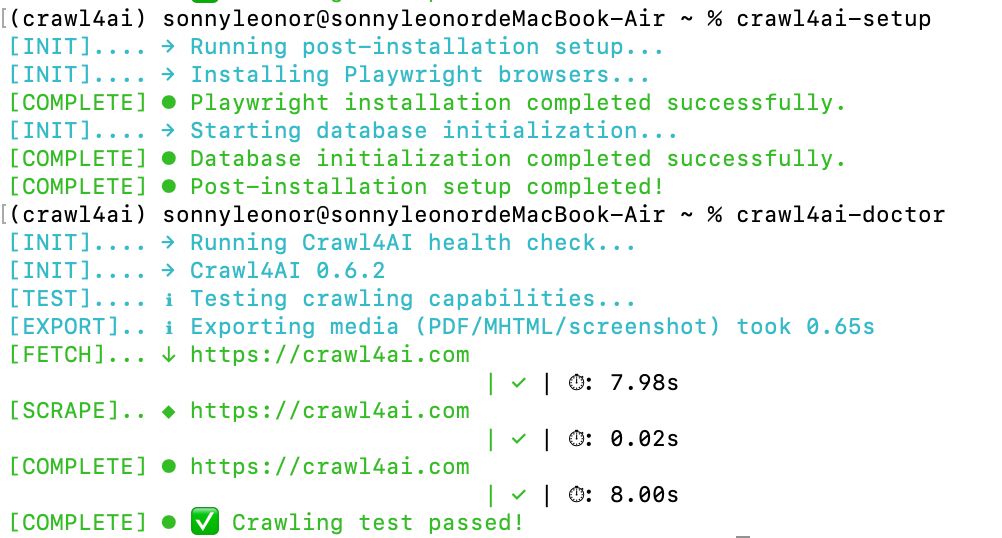
接下来我们测一下官方给的示例。
_import_ asyncio
_from_ crawl4ai _import_ *
async def **main**():
_async_ _with_ AsyncWebCrawler() _as_ crawler:
result = _await_ crawler.arun(
_url_="https://www.nbcnews.com/business",
)
print(result.markdown)
_if_ __name__ == "__main__":
asyncio.run(main())
官方的测试是一个新闻网站,但被墙了,需要 🪜
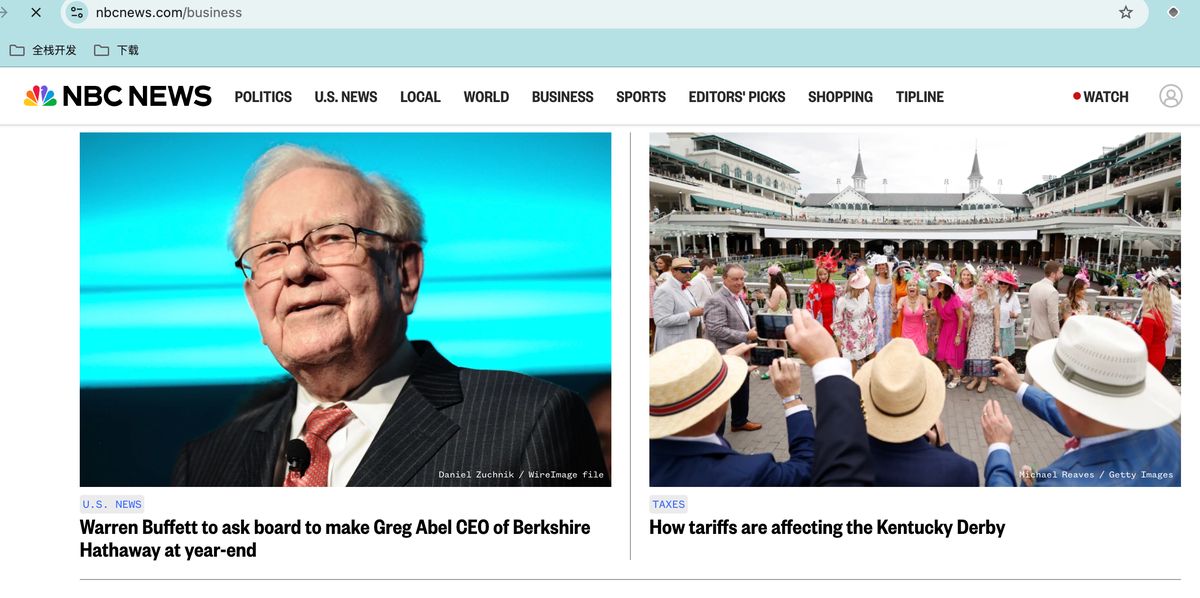
新建 py 文件,把代码黏贴进去,直接运行后,结果显示,确实能正常抓取。
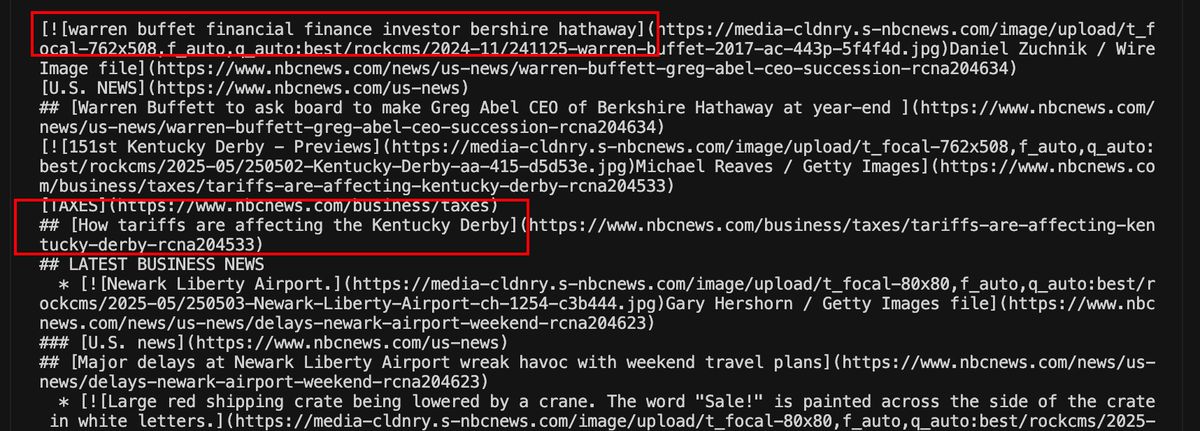
提取表格
最新版的 Crawl4ai 有个新的功能:把网站上的表格抓取下来后,解析成 pandas 的 DataFrame 格式。
简单来说,之前我们需要手动去把下载下来的数据,清洗、结构化后,转成 DataFrame 格式再做分析。
现在是可以一步到位了。

我们看下这个官方示例给的是一个虚拟货币的网站,我们需要把下图中的表格给爬下来,并转成 python 的表格,可以直接用于下一步分析。
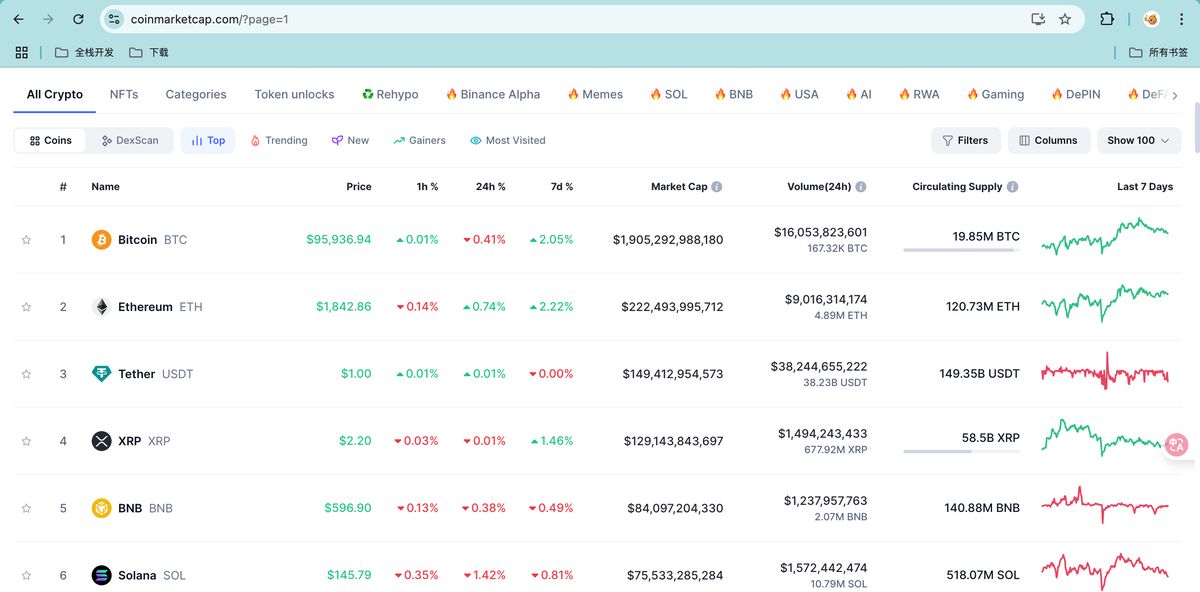
但这里出了一个问题:官方给的示例无法用,如图,是不完整的,都是红色波浪线,直接运行会报错,我代码能力又差,不会改,怎么办?
很简单,让 AI 去改就好了。直接上 Cursor。
但接下来又有新问题:因为这是 crawl4ai 的新功能,有些 AI 应该是没有学习的。
此时就可以用我们之前介绍的context7MCP,让 AI 自己去学习最新的文档,再来补全代码。
我用的提示词:
文件代码是crawl4ai的官方示例,效果是把如图 的网站表格数据抓取下来,保存为pandas的dataframe格式
但这个代码不完整,需要你用context7 mcp 找到最新的crawl4ai文档,把代码补充完整确保能正常使用
AI 一顿操作之后,拿到的代码直接运行就能跑了,我们看到已经顺利把前面网站里的表格下载成了 DF
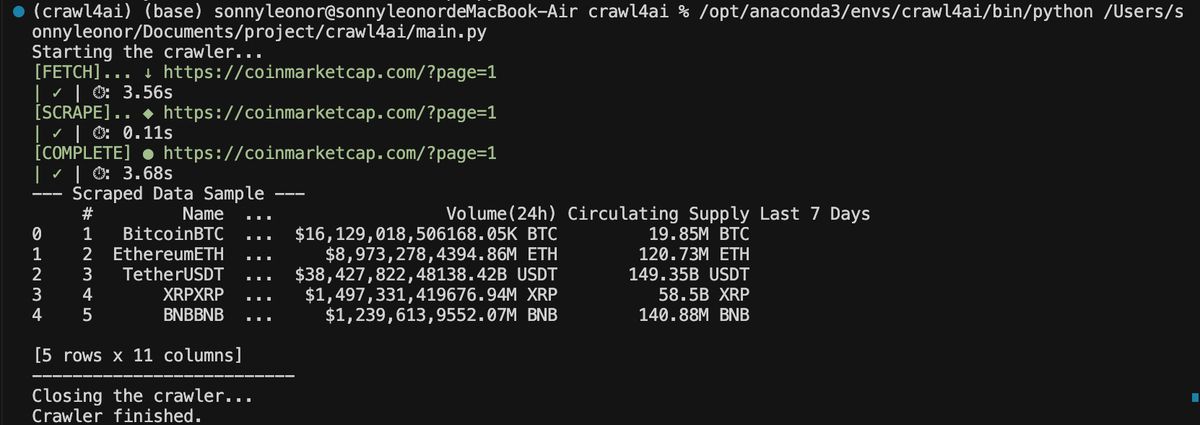
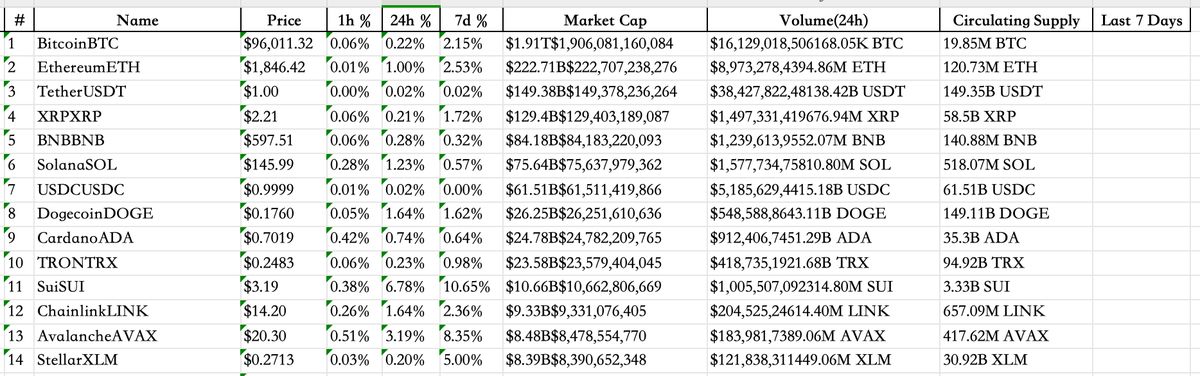
还是挺顺利的,打开 Excel 看更完整一些,接下来就能用这些数据做分析。
动态加载
现在的网站很少静态了,大多数都是动态加载,也就是需要不断滚动才会加载新的内容,如果这个流程要自己处理就太麻烦了。
幸好,Crawl4ai 内置了 javascript 的支持,我们可以直接写一句 js 代码,就能让页面一滚到底把所有内容加载。
result = await crawler.arun(
url="https://动态内容站点.com",
js_code="window.scrollTo(0, document.body.scrollHeight);",
wait_for="document.querySelector('.loaded')"
)
OK,至此,我们已经跑通了 Crawl4ai 官方给的爬虫示例代码。但还没用上 AI 的地方。
要知道,我们之所以用这些框架,就是想让 AI 来帮我们解决爬虫中的难题。
所以接下来我们来看下怎么在 Crawl4ai 用 AI 来做爬虫?
进阶:大模型动态加载爬取电商评论
还是业务场景先行,我选择了一个高频的场景:电商商品评论爬取。(后续爬下来的评论数据还可以做文本分析,挖掘出有商业价值的信息)
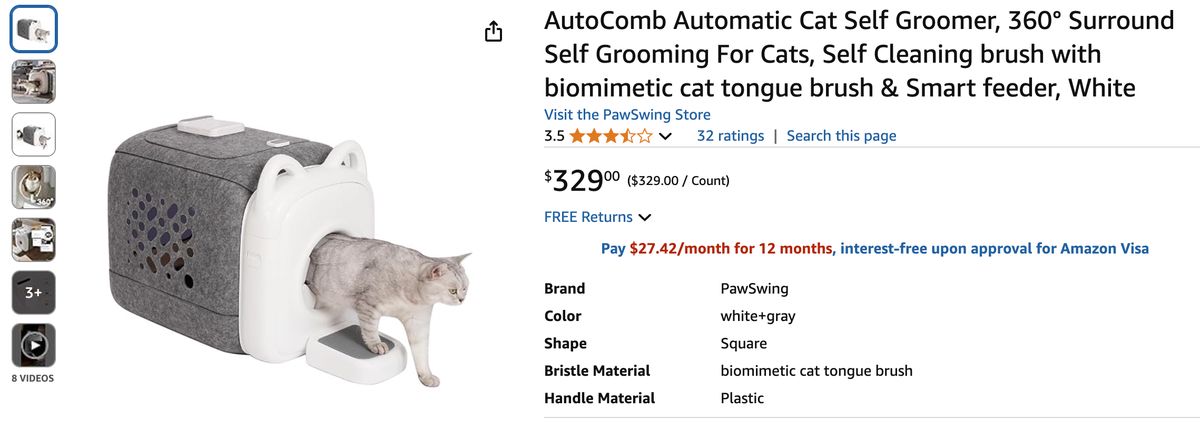
网址是:
https://www.amazon.com/PawSwing-AutoComb-Automatic-Surround-biomimetic/dp/B0DMSVNTC1
往下翻能看到评论列表:
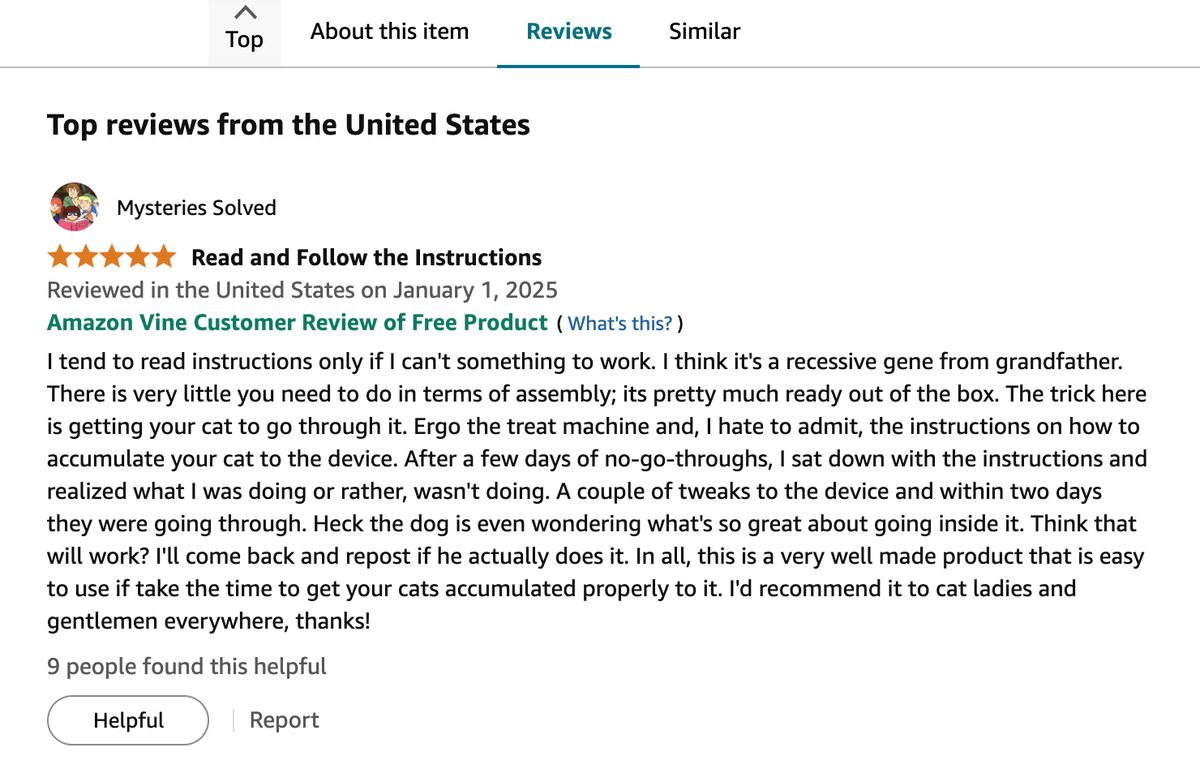
利用 playwright MCP 初始化脚本
在原先 Cursor 的窗口下,直接让 AI 先帮我们完成代码的撰写:
现在需要你写一个Crawl4ai的脚本,把这个亚马逊产品下的评论抓取出来:顾客姓名、标题、国家、时间、评论内容等,你可以先用playwright mcp去看一下这个网站,然后再修改
发现没有,我没有让 AI 直接去写代码,而是让它先去看一眼这个网站长什么样,然后再写代码。
因为每个网站加载流程、速度、结构都是不同的,贸贸然写一个通用的代码,很可能跑不通。
而 Playwright MCP 的介绍与安装我之前也说过,可以直接跳转这个文章去学习。
话说回来,我们已经能看到 AI Called MCP tool,自动打开亚马逊网站,并且 get_visible_html,也就是看了一眼。

得到的代码如下,整体很长,我截了一些关键部分,包括建议也放到了注释里:
_# 1. 定义亚马逊评论的数据模型_
class AmazonReview(BaseModel):
customer_name:
review_title:
country_and_date:
review_body:
image_urls:
rating:
_# 2. 使用LLMConfig来配置AI模型_
llm_config = LLMConfig(
_provider_=_provider_,
_api_token_=_api_token_,
_base_url_=_base_url_
)
# 3. 设置AI爬取数据的策略,关键就是提示词
strategy = LLMExtractionStrategy(
_llm_config_=llm_config,
_schema_=AmazonReview.model_json_schema(),
_extraction_type_="schema",
_instruction_=f"""
从提供的HTML内容中提取亚马逊产品评论信息。
评论通常包含在一个带有 'data-hook="review"' 属性的<div>元素中。
请为每个评论提取以下信息,并构造成一个JSON对象列表:
1. `customer_name`: 评论者的名字,通常在一个带有 'data-hook="genome-widget"' 的span元素内或附近。
2. `review_title`: 评论的标题,通常在一个带有 'data-hook="review-title"' 的span或a元素内,可能是加粗的文本。
3. `country_and_date`: 评论的国家和日期,通常在一个带有 'data-hook="review-date"' 的span元素内,格式类似于 "Reviewed in [国家] on [日期]"。
4. `review_body`: 评论的正文内容,通常在一个带有 'data-hook="review-body"' 的span元素内。
5. `image_urls`: 评论中用户上传的图片URL列表。图片通常是<img>标签,其父元素可能带有 'review-image-tile' 或类似class。请提取<img>标签的'src'属性。如果没有图片,则此字段为null或空列表[]。
6. `rating`: 评论的星级评分,通常在评论标题附近或评论正文开头。
确保提取尽可能多的评论。忽略页面上非评论区域的内容。
""",
_chunk_token_threshold_=8000, _# 改回合理的分块阈值_
_apply_chunking_=True, _# 对大型页面进行分块处理_
_input_format_="html",
_verbose_=True _# 开启LLM策略的详细日志_
)
# 4. 对浏览器的设置,尤其是反爬厉害的网站一定要设置
browser_config = BrowserConfig(
_headless_=False, _# 可以设为True在后台运行_
_java_script_enabled_=True, _# 确保JavaScript加载评论_
_# 可以添加代理、user-agent等配置来模拟真实用户,减少被屏蔽的风险_
_# user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"_
_viewport_={"width": 1280, "height": 800},
_verbose_=True _# 开启浏览器配置的详细日志_
)
# 5. 爬虫配置
crawler_config = CrawlerRunConfig(
_cache_mode_=CacheMode.BYPASS,
_page_timeout_=90000, _# 增加页面加载超时时间,亚马逊页面可能较慢_
_extraction_strategy_=strategy,
_# 增加等待时间,确保动态加载的评论内容出现_
_# 注意:crawl4ai目前没有直接的wait_for_selector或类似playwright的精细等待机制_
_# 可以通过 page_timeout 间接控制等待时间,或者后续考虑用playwright直接操作_
_verbose_=True _# 开启爬虫运行的详细日志_
)
# 6. 开始爬取
result = _await_ crawler.arun(
_url_=_self_.url,
_config_=_self_.crawler_config,
_js_code_="window.scrollTo(0, document.body.scrollHeight);",
_wait_for_="document.querySelector('.loaded')"
)
完成爬取
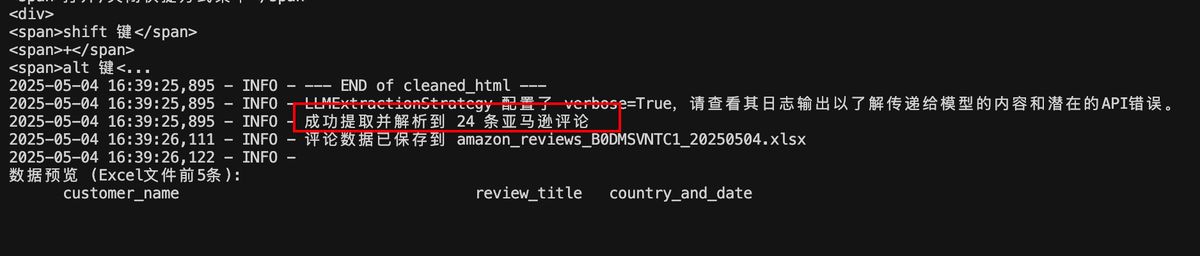
看下结果还是不错的
尤其是 image_url 能直接把图片地址整理好。
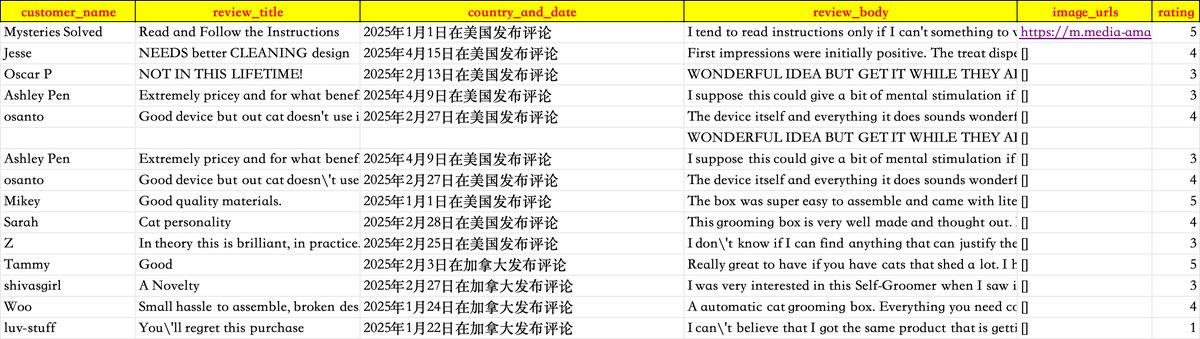
Crawl4ai****的逻辑是会一开始先把 HTML 全部扔给 AI 然后让 AI 出解析的策略,再拆分成多个模块逐个给到 AI 去解析数据。
这里就有个要点:选择模型要注意支持「大上下文」的
我一开始选的 deepseek v3 ,太小了,导致一开始啃不下整个 HTML 导致报错
后来我改用 gemini-2.5-pro-exp-03-25 才成功
很烧 token,大家可以感受一下,我抓了 24 条评论,消耗了多少:
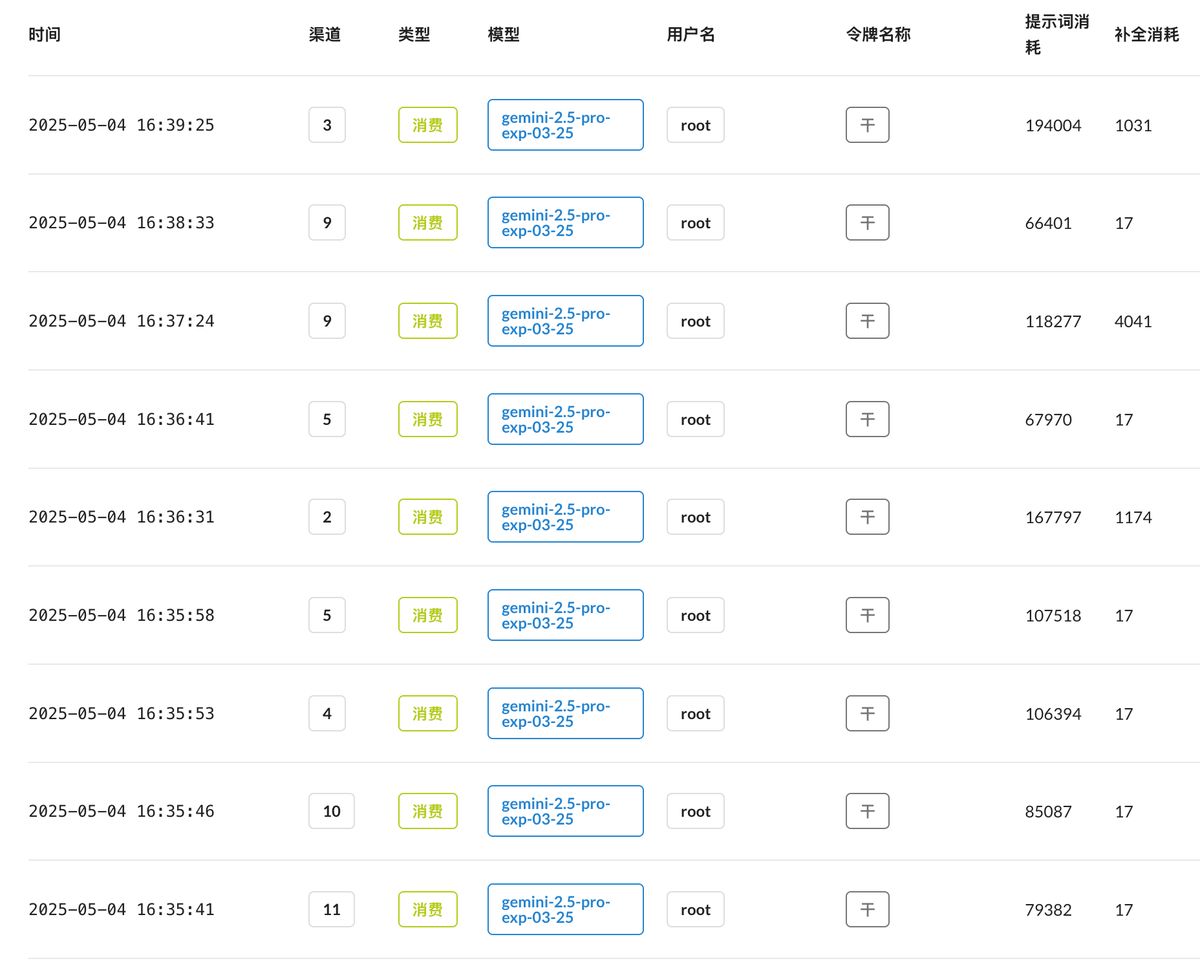
总消耗:992,830 (Prompt) + 6,348 (Completion) = 999,178 tokens
如果 gemini-2.5-pro-preview-03-25 的费用来算,大概是 1.3 美金(Gemini 帮我算的,幸好我用的是免费的版本。)
总结
说实话,爬虫的话 RPA 效果好很多,但 RPA 似乎是一个伪命题,需要自己去搭流程、去抓元素、去设计抓取逻辑等等,一个无代码工具反而让小白无所适从,得从头好好学习才行。
现在 AI 爬虫比较可行的方案是基于 Cursor,搭配 Playwright MCP 去开发 Crawl4ai 的脚本。
虽然现在还不是非常好用,但或许在不久的未来会是一个很丝滑的 AI 爬虫体验。