摘要
数据分析师分享PandasAI+DeepSeek实战经验,通过自然语言查询替代复杂代码编写,实现数据分析效率翻倍,包含安装配置、多表分析和可视化完整指南。

作为从业 10 年的数据分析师,饼干哥哥目前在一家上市公司做数据分析主管,给公司从 0 到 1 搭建数据库、建立起了数据分析体系。
随着业务发展、基建完善,数据分析的需求也变得非常多了。每天工作量都很大,如果还像以前那样,「老老实实」一行一行代码的敲,估计每天加班都干不完。
幸好 AI 来了,我工作流中大量使用 AI 解决问题,后面我也会陆陆续续分享出来,可以关注一下 GZH 「饼干哥哥 AGI」
数据分析一定离不开 Python 的 Pandas 模块,具体可以看我之前的一些介绍。
今天要分享的是 Pandas 的 AI 版本——PandasAI,再加上 DeepSeek 前段时间新出的 v3 0324 版,现在已经可以很稳定的帮助我们输出数据分析结果了。
什么是 PandasAI

PandaAI is a Python platform that makes it easy to ask questions to your data in natural language. It helps non-technical users to interact with their data in a more natural way, and it helps technical users to save time, and effort when working with data.
说白了,就是能在 Python 中,通过自然语言向 Pandas 提需求,把需求的结果直接给到我们,帮助我们省去中间复杂的敲代码过程。
具体可见 https://github.com/sinaptik-ai/pandas-ai
接下来,带大家实战看看这个工具怎么用?
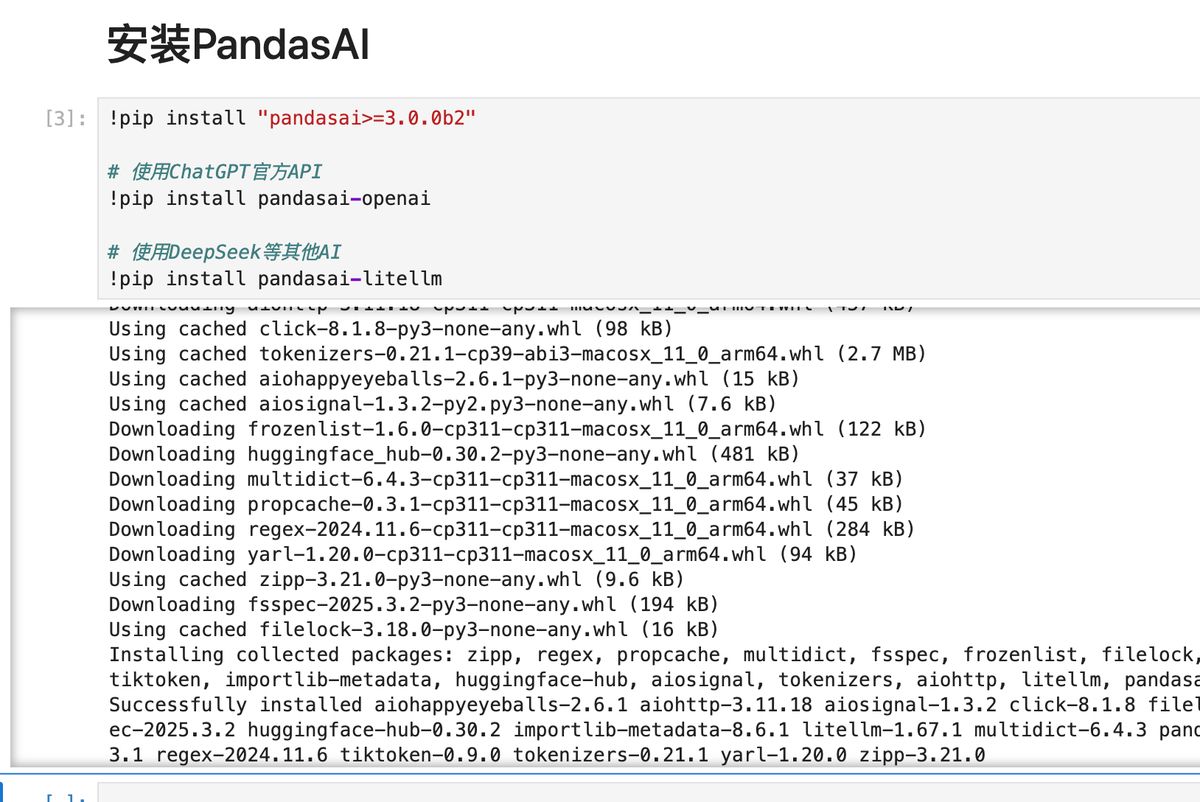
安装 PandasAI
用 pip 常规安装:
pip install "pandasai>=3.0.0b2"
# 使用ChatGPT官方API
pip install pandasai-openai
# 使用DeepSeek等其他AI
pip install pandasai-litellm
小技巧:在 Jupyter 里,直接在命令前加上感叹号
!就能调用命令行来安装了。
安装完后,有两种方式调用 AI
一种是直接用 PandasAI 内置的大模型,是它自己开发的,可以到官网去注册申请。效果不知道,好像是有一定 的免费额度,感兴趣可以自己去注册试下 https://app.pandabi.ai/
第二种,就是用第三方的 AI,例如 DeepSeek,就需要按图中的参数去做配置,**关键的地方在于 model的配置,因为不同的渠道可能 AI 的配置方式是不同的,所以需要先指定模型的协议类型,正常就是openai,也就是说,要在正常模型前加上****openai/**才可以
import os
import pandasai as pai
from pandasai_litellm import LiteLLM
# 这是DeepSeek官方的API,但我没充钱
# model="openai/deepseek-chat" # add `openai/` prefix to model so litellm knows to route to OpenAI
# api_key="sk-7a83c039...." # api key to your openai compatible endpoint
# api_base="https://api.deepseek.com/v1" # set API Base of your Custom OpenAI Endpoint
# 这是火山引擎的,如果你是其他渠道的话,照葫芦画瓢就行
model="openai/ep-20250316174127-8v2jz" # 重点是这里,要在正常的模型前加 `openai/` 证明是符合 openai 标准的
api_key="1638c638-c730...."
api_base="https://ark.cn-beijing.volces.com/api/v3/"
llm = LiteLLM(model=model, api_key=api_key, api_base=api_base)
# Set your LLM configuration
pai.config.set({"llm": llm})

ok,至此我们就完成了 PandasAI 的安装与配置。
用 PandasAI 做数据分析
接下来进入业务分析实战,看看它的效果如何。
首先,我这里用到的是我之前做 618 电商分析直播分享时候的数据集。
大概长这样:就是每天的订单数据。
首先,导入数据。
很简单,但也有坑: 数据集要求是 1. 英文无空格;2. csv 文件,我试了 xlsx 会报错
df = pai.read_csv("dataset.csv")
print('完成加载数据')
response = df.chat("给我这个数据集的描述统计信息")
导入后,就可以直接调用 .chat 来开始用 AI 来做分析了。
首先,先看简单的让 AI 给我做一份描述性统计。
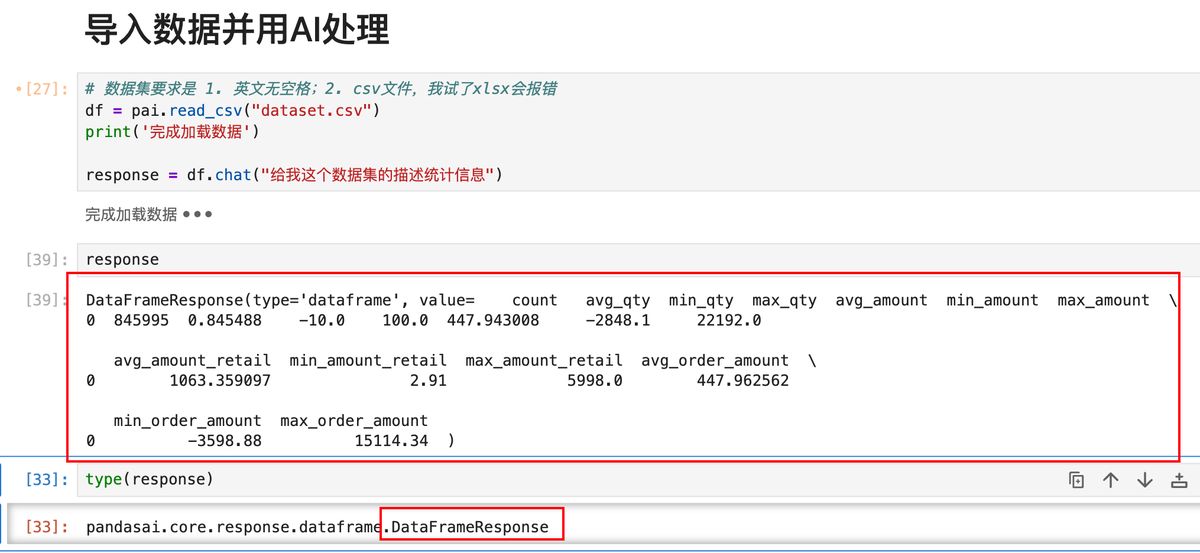
如上图,一段时间后,就能看到结果了。
这里我们发现,返回的结果是 DataFrameResponse,是 PandasAI 自己设计的数据类型。
再仔细看,这是个元组,里面有两个属性 type 说这是 dataframe,value 就是具体的内容。
所以我们可以通过 .value 的形式把 dataframe 提取出来,如下图所示。
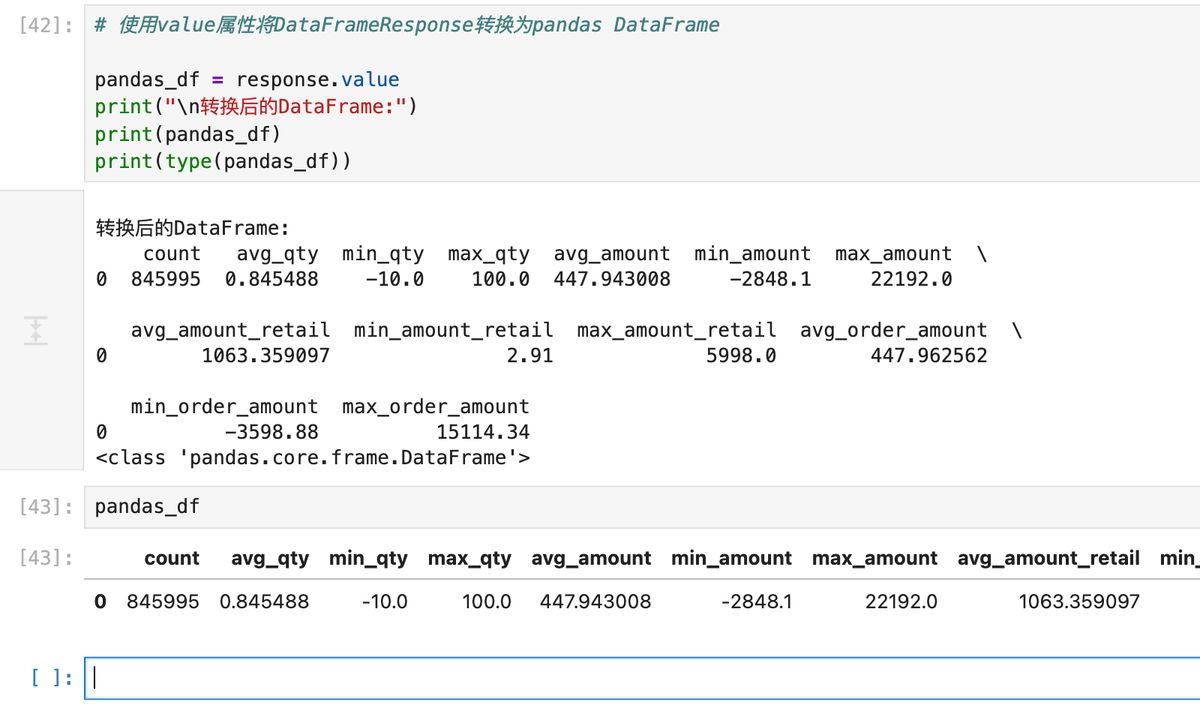
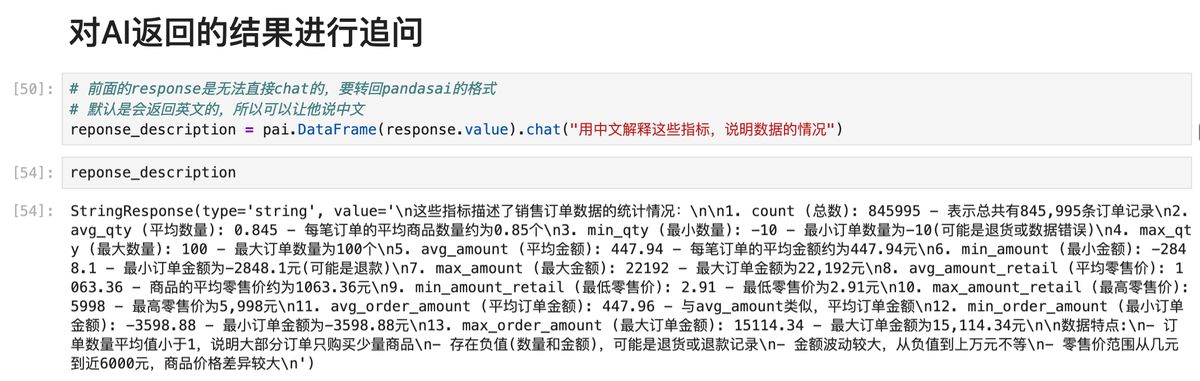
对 AI 结果追问
以上就是最简单也是最常用的 AI 用法。
接着,按照基操,我们往往需要根据结果进行追问。但不能直接对结果进行 AI 提问,否则会报错。
正确的打开方式是,重新用pai.DataFrame把表装进去再**.chat**
如下图所示。
疑问?分析的结果到底对不对?
我们可以看到 AI 的分析是一个黑箱过程,到底给的结果对不对呢?接下来我们要验证一下。
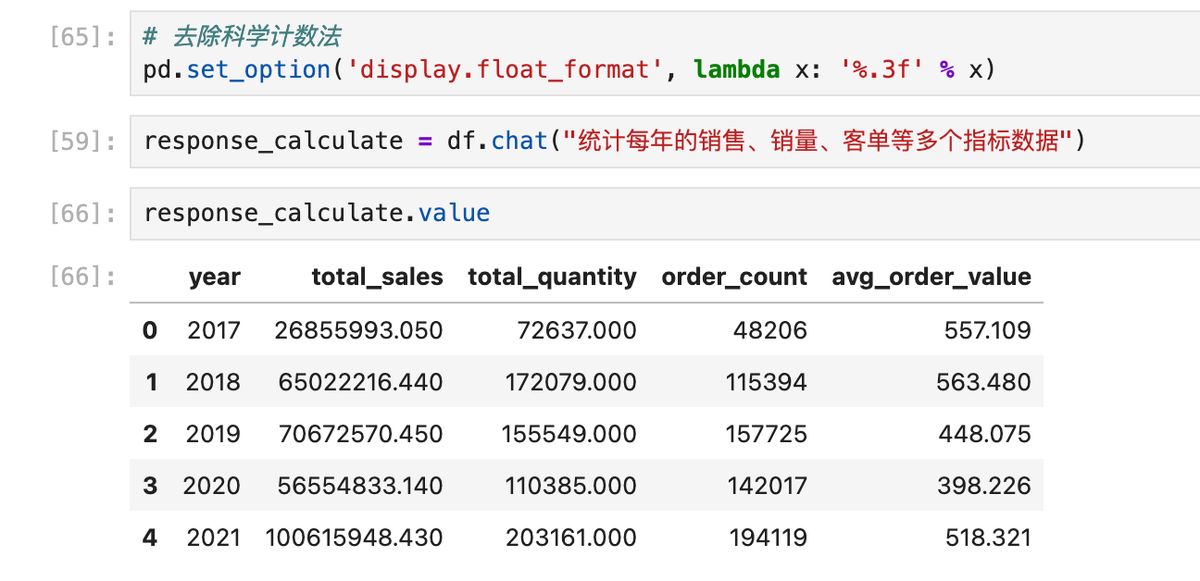
同时,也把分析的难度再做升级:对订单按年统计数据。
下图,就一句话让 AI 计算的结果。
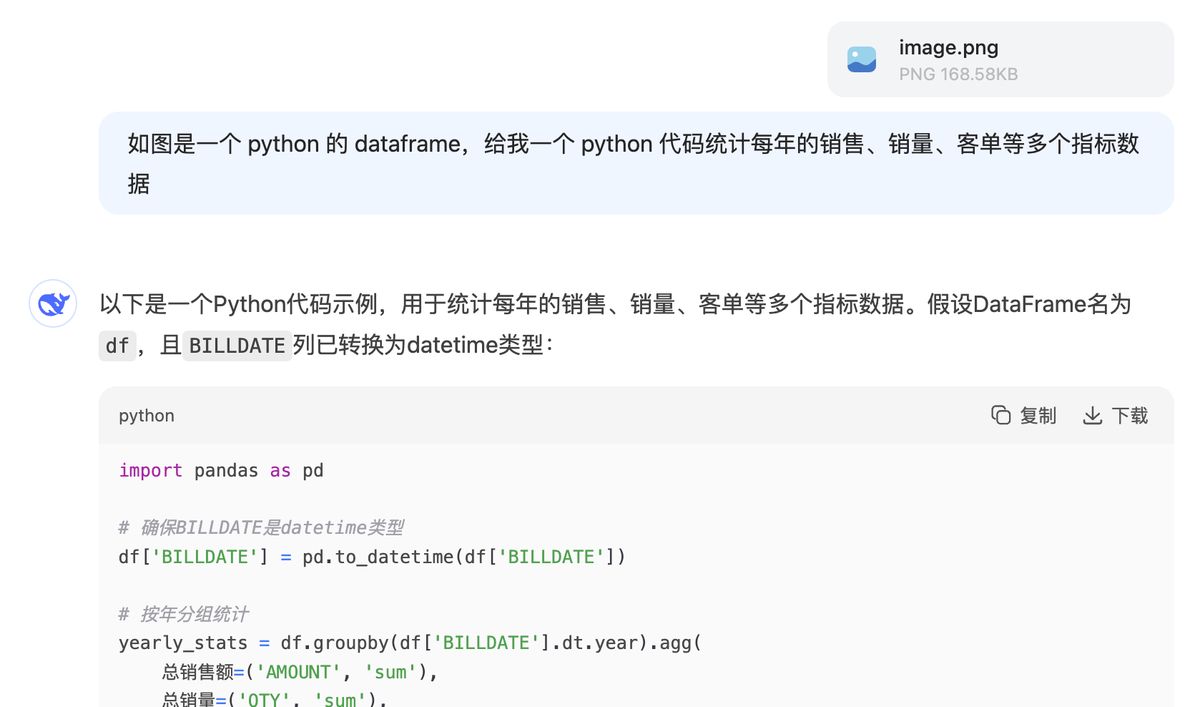
我们看下,不用 AI 传统,我们自己是要怎么计算

一顿操作后,惊讶发现,数据结果跟 AI 做的是一样的。
对比下来,我们自己操作就复杂了很多,明显不符合新时代的玩法,所以其实这段代码也是我让 DeepSeek 生成的,这样就能对关键的部分做二次验证。
由此可以看到,AI 在数据分析方面的提效已经非常成熟了。
做可视化图表
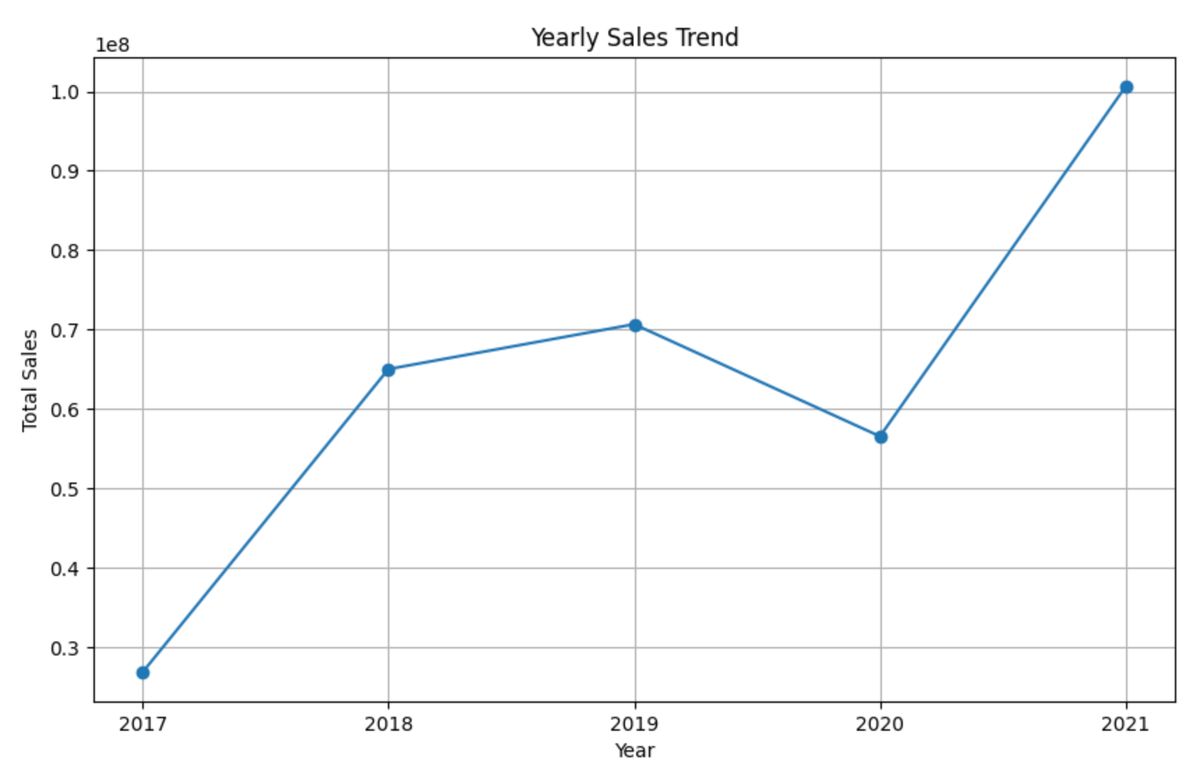
实际上 PandasAI 还能做图表 📈,我们看看是怎么个事。
还是用前面 AI 返回的每年统计数据的表格,让它做一个销售趋势图。
它会在本地新建一个文件夹,存它做好的图
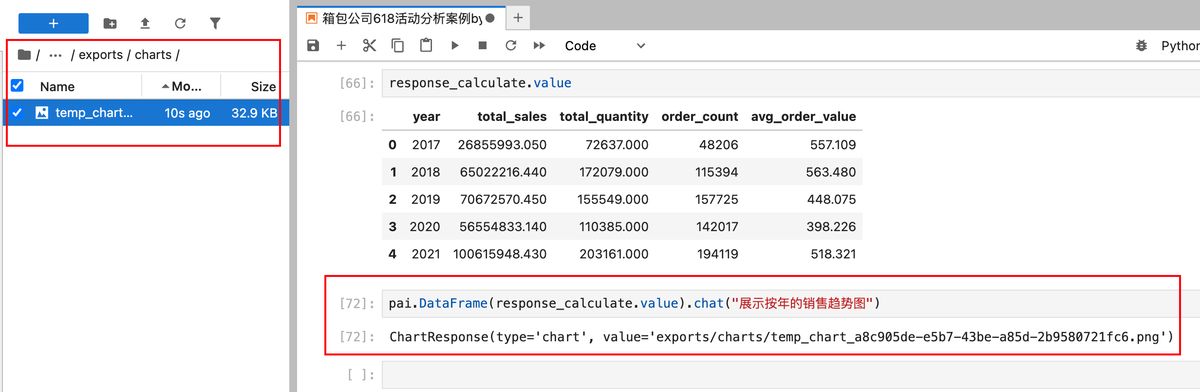
长这样,明显就是用 matplotlib 做的,效果还行吧。
多表交叉分析
以上是很基础的分析场景,也就是说真实业务中并没有这么简单。
由于数据量的关系,很多时候,数据是分散在多个表格的,也就是需要做多表连接之后再分析。
幸好,PandasAI 也支持。
我模拟了最常见的 产品表、用户表、订单表数据,给了一个需求 按城市统计,每个城市的销售额是多少?
这样就需要把三个表连起来分析了。
# 产品表
products_data = {
'ProductModel': ['M100', 'M200', 'M300', 'M400', 'M500'],
'Price': [100,200,300,400,500]
}
# 用户表
users_data = {
'UserID': ['U001', 'U002', 'U003', 'U004', 'U005'],
'City': ['Guangzhou', 'Beijing', 'Guangzhou', 'Beijing', 'Beijing']
}
# 订单表
orders_data = {
'OrderDate': ['2023-01-15', '2023-01-16', '2023-01-17', '2023-01-18', '2023-01-19'],
'OrderID': ['O1001', 'O1002', 'O1003', 'O1004', 'O1005'],
'ProductModel': ['M100', 'M200', 'M300', 'M400', 'M500'],
'UserID': ['U001', 'U002', 'U003', 'U004', 'U005']
}
products_df = pai.DataFrame(products_data)
users_df = pai.DataFrame(users_data)
orders_df = pai.DataFrame(orders_data)
pai.chat("按城市统计,每个城市的销售额是多少?", products_df, users_df, orders_df)
结果:
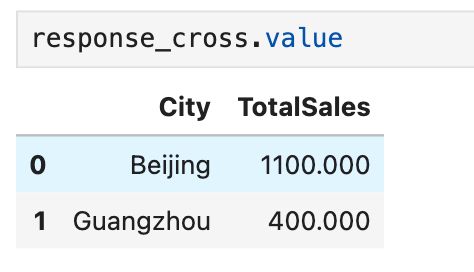
完整体验下来,PandasAI 的使用还是很丝滑的,非常推荐大家去玩一下。
今天示例代码和数据集,我放到了公众号后台
关注 GZH「饼干哥哥 AGI」
回复「pandasai」即可获取